1 + 1[1] 2Hi there! this is the material for the first lecture. To sign up, check out the welcome page
… in which we get started with R and RStudio, learn about literate programming and build our first plot by discovering a Grammar of Graphics.
Throughout your scientific career — and potentially outside of it — you will encounter various forms of data. Maybe you do an experiment and measured the fluorescence of a molecular probe, or you simply count the penguins at your local zoo. Everything is data in some form or another. But raw numbers without context are meaningless and tables of numbers are not only boring to look at, but often hide the actual structure in the data.
In this course you will learn to handle different kinds of data. You will learn to create pretty and insightful visualizations, compute different statistics on your data and also what these statistical concepts mean. From penguins to p-values, I got you covered.
The course will be held in English, as the concepts covered will directly transfer to the research you do, where the working language is English. That being said, feel free to ask questions in any language that I understand, so German is also fine. My Latin is a little rusty, thought.
In this course, we will be using the programming language R. R is a language particularly well suited for data analysis, because it was initially designed by statisticians and because of the interactive nature of the language, which makes it easier to get started. So don’t fret if this is your first encounter with programming, we will take one step at a time.
The datasets chosen to illustrate the various concepts and tools are not particularly centered around Biology. Rather, I chose general datasets that require less introduction and enable us to focus on learning R and statistics. This is why we will be talking about penguins, racing games or life expectancy instead of intricate molecular measurements.
You can now execute commands in the R console in the bottom left. For example we can calculate a mathematical expression:
1 + 1[1] 2Or generate the numbers from one to 10:
1:10 [1] 1 2 3 4 5 6 7 8 9 10But I rarely type directly into the console. Because we want our results to be reproducible, we write our code in a script first, so that the next person 1 can see what we did and replicate our analysis. You will see that reproducibility is quite near and dear to me, so it will pop up once or twice. And as scientists, I am sure you understand the importance.
1 This will most likely be future You. And you will thank yourself later
A script is like a recipe. It is the most important part of your data analysis workflow, because as long as you have the recipe, you can recreate whatever products (e.g. plots, statistics, tables) you have with ease.
To create a new script, click the little button in the top left corner. In a script you can type regular R code, but it won’t get executed straight away. To send a line of code to the console to be executed, hit Ctrl+Enter. Go ahead, try it with:
Before we get deeper into R, let’s talk a little bit about our Home when working with R: RStudio.
There is one important setting that I would like you to change: Under Tools -> Global Options make sure that “Restore .RData into workspace at startup” is unchecked. The workspace that RStudio would save as .RData contains all objects created in a session, which is, what we can see in the Environment pane (by default in the top right panel, bottom right in my setup). Why would we not want to load the objects we created in the last session into our current session automatically? The reason is reproducibility. We want to make sure that everything our analysis needs is in the script. It creates our variables and plots from the raw data and should be the sole source of truth.
Check out the lecture video for further customization of RStudio e.g. with themes and make sure to also use RStudio Projects to structure your work.
R can do lot’s of things, but let’s start with some basics, like calculating. Everything that starts with # is a comment and will be ignored by R.
1 + 1 # addition[1] 232 / 11 # division[1] 2.9090913 * 4 # multiplication[1] 1213 %% 5 # modulo[1] 313 %/% 5 # integer division[1] 2Create vectors with the : operator, e.g. numbers from:to
1:4[1] 1 2 3 4And mathematical operations are automatically “vectorized”:
1:3 + 1:3[1] 2 4 6In fact, R as no scalars (individual values), those are just vectors of length 1.
Often, you will want to store the result of a computation for reuse, or to give it a sensible name and make your code more readable. This is what variables are for. We can assign a value to a variable using the assignment operator <- (In RStudio, there is a shortcut for it: Alt+Minus):
my_number <- 42Executing the above code will not give you any output, but when you use the name of the variable, you can see its content.
my_number[1] 42And you can do operations with those variables:
x <- 41
y <- 1
x + y[1] 42NOTE Be careful about the order of execution! R enables you to work interactively and to execute the code you write in your script in any order with
Ctrl+Enter, but when you execute (=“source”) the whole script, it will be executed from top to bottom.
Furthermore, code is not executed again automatically, if you change some dependency of the expression later on. So the second assignment to x doesn’t change y.
x <- 1
y <- x + 1
x <- 1000
y[1] 2Variable names can contain letters (capitalization matters), numbers (but not as the first character) and underscores _. 2
2 They can also contain dots (.), but it is considered bad practice, because it can lead to some confusing edge cases.
# snake_case
main_character_name <- "Kvothe"
# or camelCase
bookTitle <- "The Name of the Wind"
# you can have numbers in the name
x1 <- 12
A good convention is to always use snake_case.
First we have numbers (which internally are called numeric or double)
12
12.5Then, there are whole numbers (integer)
1L # denoted by Las well as the rarely used complex numbers (complex)
1 + 3i # denoted by the small i for the imaginary partText data however will be used more often (character, string). Everything enclosed in quotation marks will be treated as text. Double or single quotation marks are both fine.
"It was night again."
'This is also text'Logical values can only contain yes or no, or rather TRUE and FALSE in programming terms (boolean, logical).
TRUE
FALSEThere are some special types that mix with any other type. Like NULL for no value and NA for “Not Assigned”.
NULL
NANA is contagious. Any computation involving NA will return NA (because R has no way of knowing the answer):
NA + 1[1] NAmax(NA, 12, 1)[1] NABut some functions can remove NAs before giving us an answer:
max(NA, 12, 1, na.rm = TRUE)[1] 12You can ask for the datatype of an object with the function typeof:
typeof("hello")[1] "character"There is also a concept called factors (factor) for categorical data, but we will talk about that later, when we get deeper into vectors.
In R, everything that exists is an object, everything that does something is a function.
Functions are the main workhorse of our data analysis. For example, there are mathematical functions, like sin, cos etc.
sin(x = 0)[1] 0Functions take arguments (sometimes called parameters) and sometimes they also return things. The sin function takes just one argument x and returns its sine. What we do with the returned value is up to us. We can use it directly in another computation or store it in a variable. If we don’t do anything with the return value, R simply prints it to the console.
Note, that the = inside the function parenthesis gives x = 0 to the function and is separate from any x defined outside of the function. For example:
x <- 10
cos(x = 0)[1] 1# x outside of the function is still 10
x[1] 10To learn more about a function in R, execute ? with the function name or press F1 with your mouse over the function. This is actually one of the most important things to learn today, because the help pages can be… well… incredibly helpful.
?sinWe can pass arguments by name or by order of appearance. The following two expressions are equivalent.
sin(x = 12)
sin(12)Other notable functions to start out with:
Combine elements into a vector:
c(1, 3, 5, 31)[1] 1 3 5 31Convert between datatypes with:
as.numeric("1")[1] 1as.character(1)[1] "1"Calculate summary values of a vectore:
x <- c(1, 3, 5, 42)
max(x)[1] 42min(x)[1] 1mean(x)[1] 12.75range(x)[1] 1 42Create sequences of numbers:
seq(1, 10, by = 2)[1] 1 3 5 7 9You just learned about the functions sin, seq and max. But wait, there is more! Not only in the sense that there are more functions in R (what kind of language would that be with only two verbs?!), but also in a more powerful way:
We can define our own functions!
The syntax (\(\leftarrow\) grammar for programming languages) is as follows.
name_for_the_function <- function(parameter1, parameter2, ...) { # etc.
# body of the function
# things happen
result <- parameter1 + parameter2
# Something the function should return to the caller
return(result)
}The function ends when it reaches the return keyword. It also ends when it reaches the end of the function body and implicitly returns the last expression. So we could have written it a bit shorter and in fact you will often see people omitting the explicit return at the end:
add <- function(x, y) {
x + y
}And we can call our freshly defined function:
add(23, 19)[1] 42Got an error like Error in add(23, 19) : could not find function "add"? Check that you did in fact execute the code that defines the function (i.e. put your cursor on the line with the function keyword and hit Ctrl+Enter.).
You are not the only one using R. There is a welcoming and helpful community out there. Some people also write a bunch of functions and put them together in a so called package. And some people even went a step further. The tidyverse is a collection of packages that play very well together and also iron out some of the quirkier ways in which R works (Wickham et al. 2019). They provide a consistent interface to enable us to do more while having to learn less special cases. The R function install.packages("<package_name_here>") installs packages from CRAN a curated set of R packages.
This is one exception to our effort of having everything in our script and not just in the console. We don’t want R trying to install the package every time we run the script, as this needs to happen only once. So you can either turn it into a comment, delete it from the script, or only type it in the console. You can also use RStudio’s built-in panel for package installation.
R packages, especially the ones we will be using, often come with great manuals and help pages and I added a link to the package website for each of the packages to the hexagonal icons for each package in the script, so make sure to click the icons.
If you don’t have the link at hand you can also always find help on the internet. Most of these packages publish their source code on a site called GitHub, so you will be able to find further links, help and documentation by searching for r rstats.

Quarto enables us, to combine text with code and then produce a range of output formats like pdf, html, word documents, presentations etc. In fact, this whole website was created with Quarto. Sounds exciting? Let’s dive into it!
Open up a new Quarto document with the file extension .qmd from the New File menu in the top left corner of RStudio: File → New File → Quarto Document and choose html as the output format. I particularly like html, because you don’t have to worry about page breaks and it easily works on screens of different sizes, like your phone.
A Quarto document consists of three things:
YAML. This YAML header starts and ends with three minus signs ---.#, or text that will be bold in the output by surrounding it with **..R script file. You can insert new chunks with the button on the top right of the editor window or use the shortcut Ctrl+Alt+i.Use these to document your thoughts alongside your code when you are doing data analysis. Future you (and reviewer number 2) will be happy! To run code inside of chunks, use,the little play button on the chunk, the tried and true Ctrl+Enter to run one line, or Ctrl+Shift+Enter to run the whole chunk. Your chunks can be as large or small as you want, but try to maintain some sensible structure.
The lecture video also demonstrates the different output formats (though for the exercises we will only be using html) and the visual editor.

Go ahead and install the tidyverse packages with
install.packages("tidyverse")
So let’s explore our first dataset together in a fresh Quarto document. The setup chunk is special. It gets executed automatically before any other chunk in the document is run. This makes it a good place to load packages. The dataset we are working with today actually comes in its own package, so we need to install this as well (Yes, there is a lot of installing today, but you will have to do this only once):
install.packages("palmerpenguins")And then we populate our setup chunk with
library(tidyverse)
library(palmerpenguins)This gives us the penguins dataset (Horst, Hill, and Gorman 2020):
penguins# A tibble: 344 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen NA NA NA NA
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
7 Adelie Torgersen 38.9 17.8 181 3625
8 Adelie Torgersen 39.2 19.6 195 4675
9 Adelie Torgersen 34.1 18.1 193 3475
10 Adelie Torgersen 42 20.2 190 4250
# ℹ 334 more rows
# ℹ 2 more variables: sex <fct>, year <int>Let’s talk about the shape of the penguins object. The str function reveals the structure of an object to us.
str(penguins)tibble [344 × 8] (S3: tbl_df/tbl/data.frame)
$ species : Factor w/ 3 levels "Adelie","Chinstrap",..: 1 1 1 1 1 1 1 1 1 1 ...
$ island : Factor w/ 3 levels "Biscoe","Dream",..: 3 3 3 3 3 3 3 3 3 3 ...
$ bill_length_mm : num [1:344] 39.1 39.5 40.3 NA 36.7 39.3 38.9 39.2 34.1 42 ...
$ bill_depth_mm : num [1:344] 18.7 17.4 18 NA 19.3 20.6 17.8 19.6 18.1 20.2 ...
$ flipper_length_mm: int [1:344] 181 186 195 NA 193 190 181 195 193 190 ...
$ body_mass_g : int [1:344] 3750 3800 3250 NA 3450 3650 3625 4675 3475 4250 ...
$ sex : Factor w/ 2 levels "female","male": 2 1 1 NA 1 2 1 2 NA NA ...
$ year : int [1:344] 2007 2007 2007 2007 2007 2007 2007 2007 2007 2007 ...The penguins variable contains a tibble, which is the tidyverse version of a dataframe. It behaves the same way but prints out nicer. Both are a list of columns, where columns are (usually) vectors. We will learn more about their underlying datastructure, lists, next week.
You probably took this course because you want to build some cool visualizations for you data. In order to do that, let us talk about how we can describe visualizations. Just like language has grammar, some smart people came up with a grammar of graphics (Wilkinson et al. 2005), which was then slightly modified and turned into an R package so that we can not only talk about but also create visualizations using this grammar (Wickham 2010). The package is called ggplot2, and we already have it loaded because it is included in the tidyverse. Before looking at the code, we can describe what we need in order to create this graphic.
library(tidyverse)
library(palmerpenguins)
penguins %>%
ggplot(aes(flipper_length_mm, bill_length_mm,
color = species,
shape = sex)) +
geom_point(size = 2.5) +
geom_smooth(aes(group = species), method = "lm", se = FALSE,
show.legend = FALSE) +
labs(x = "Flipper length [mm]",
y = "Bill length [mm]",
title = "Penguins!",
subtitle = "The 3 penguin species can be differentiated by their flipper- and bill-lengths.",
caption = "Datasource:\nHorst AM, Hill AP, Gorman KB (2020). palmerpenguins:\nPalmer Archipelago (Antarctica) penguin data.\nR package version 0.1.0. https://allisonhorst.github.io/palmerpenguins/",
color = "Species",
shape = "Sex") +
theme_minimal() +
scale_color_brewer(type = "qual") +
theme(plot.caption = element_text(hjust = 0))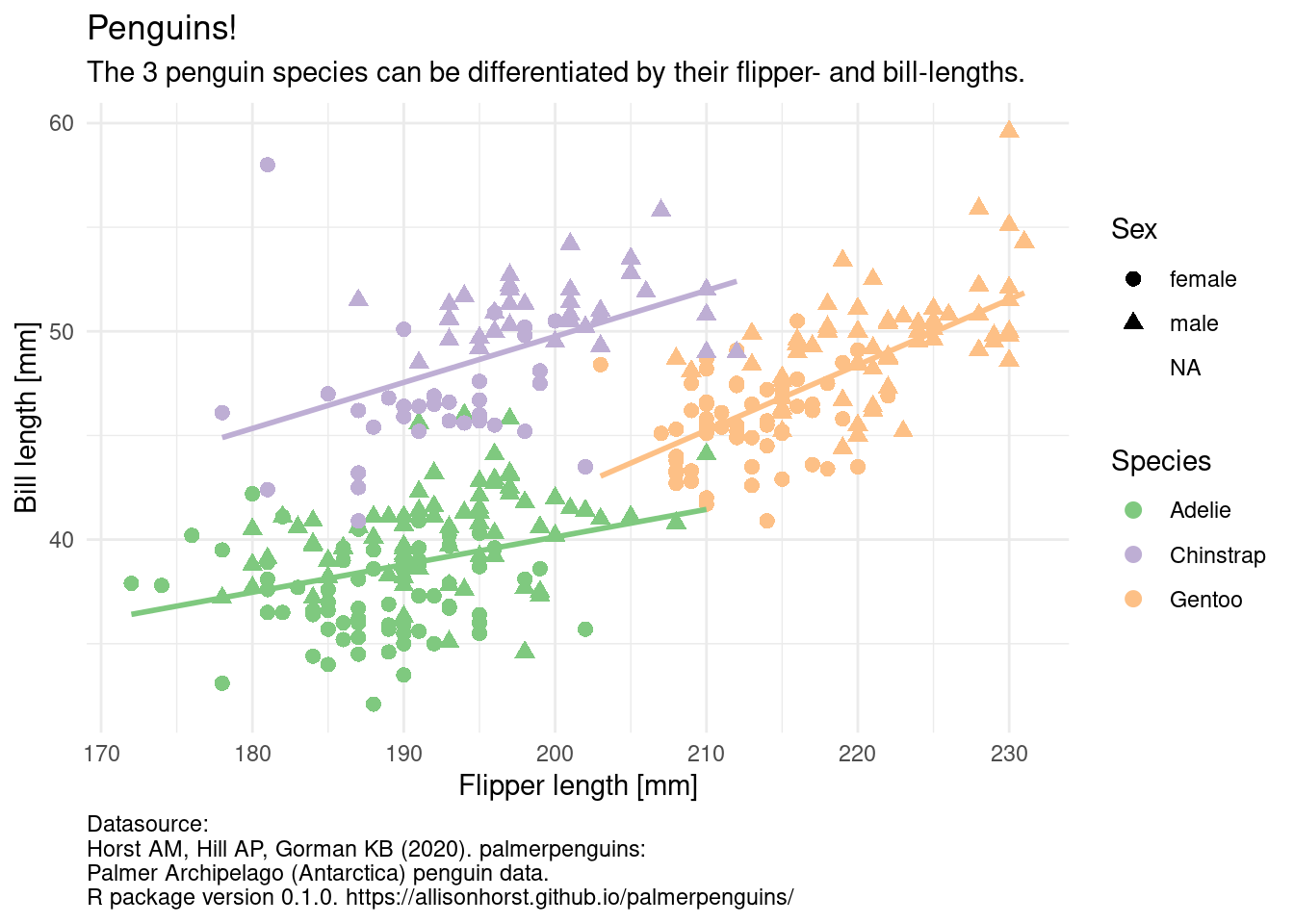
Having a grammar means: - we can build complex visualizations with basic building blocks that fit together according to some rules (the grammar) - just like lego bricks - we just have to learn the building blocks and not a different function for all the different types of plots (e.g. barplot, scatterplot, lineplot, piechart)
We can build this plot up step by step. The data is the foundation of our plot, but this just gives us an empty plotting canvas. I am assigning the individual steps we are going through to a variable, so that we can sequentially add elements, but you can do this in one step as shown above.
plt <- ggplot(penguins)
plt
Then, we add and aesthetic mapping to the plot. It creates a relation from the features of our dataset (like the flipper length of each penguin) to a visual property, like position of the x-axis, color or shape.
plt <- ggplot(penguins,
aes(x = flipper_length_mm,
y = bill_length_mm,
color = species,
shape = sex))
plt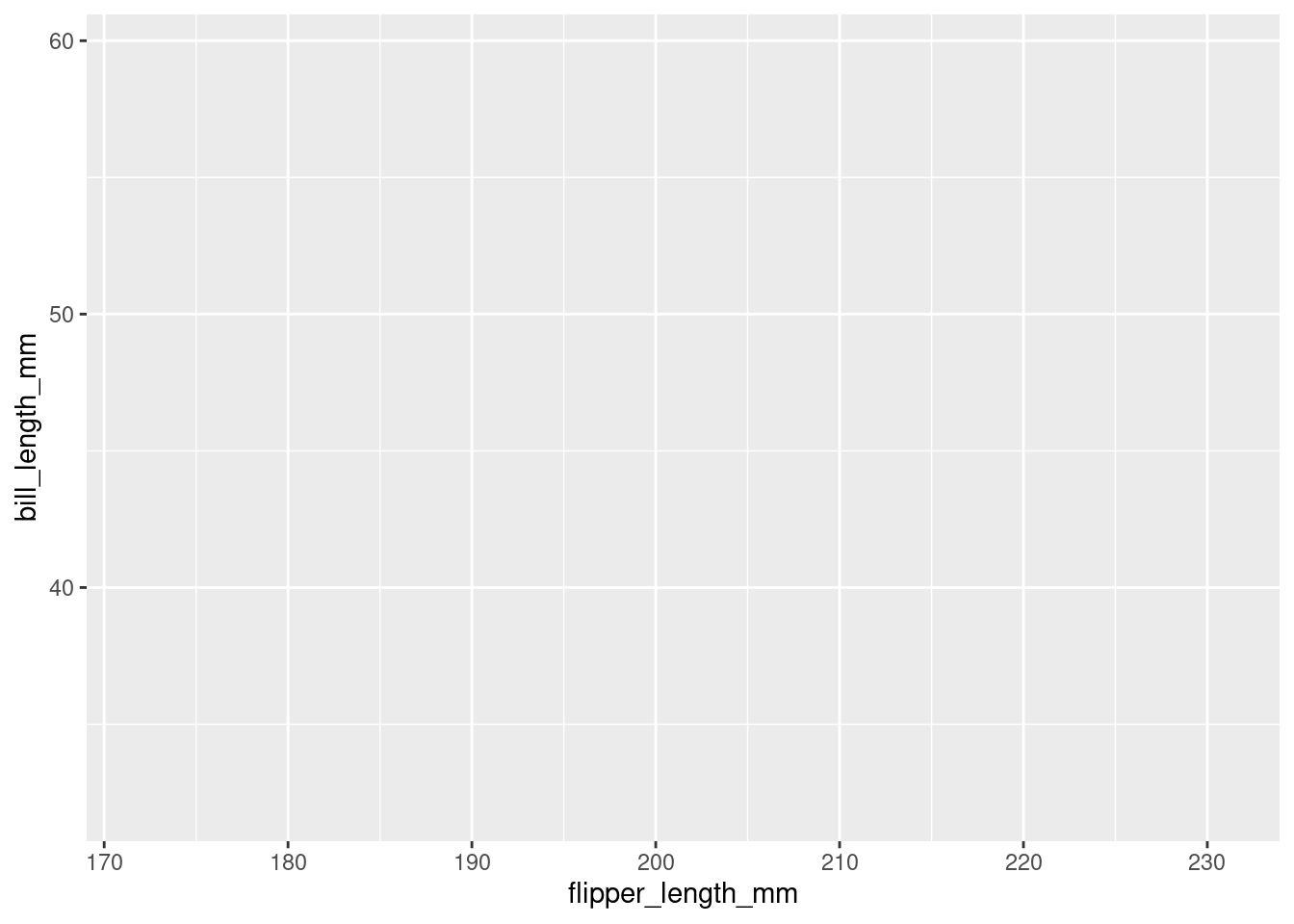
Still, the plot is empty, it only has a coordinate system with a certain scale. This is because we have no geometric objects to represent our aesthetics. Elements of the plot are added using the + operator and all geometric elements that ggplot knows start with geom_. Let’s add some points:
plt <- plt +
geom_point()
plt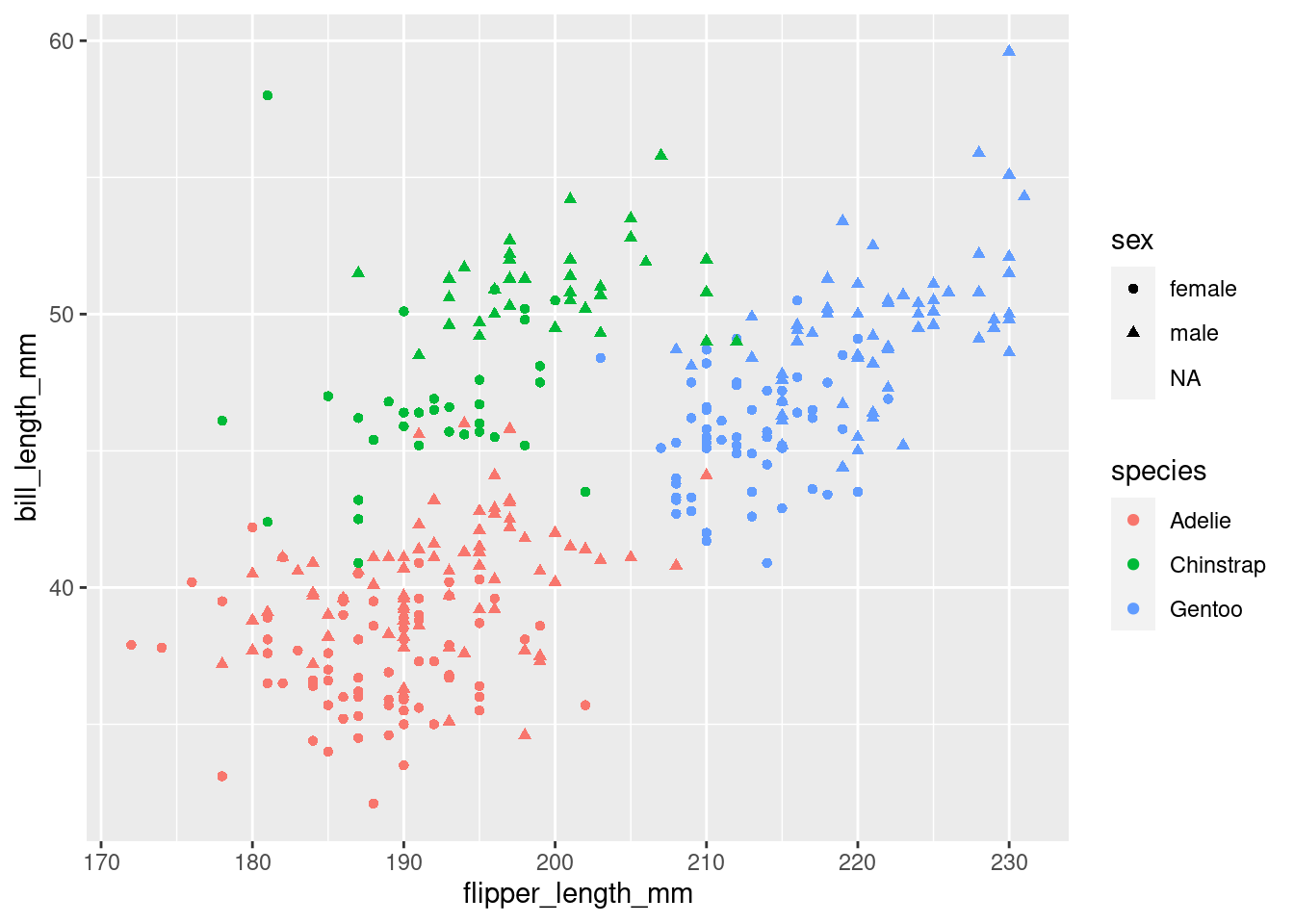
Look at the help page for geom_point to find out what aesthetics it understands. The exact way that features are mapped to aesthetics is regulated by scales starting with scale_ and the name of an aesthetic:
plt <- plt +
scale_color_manual(values = c("red", "blue", "orange"))
plt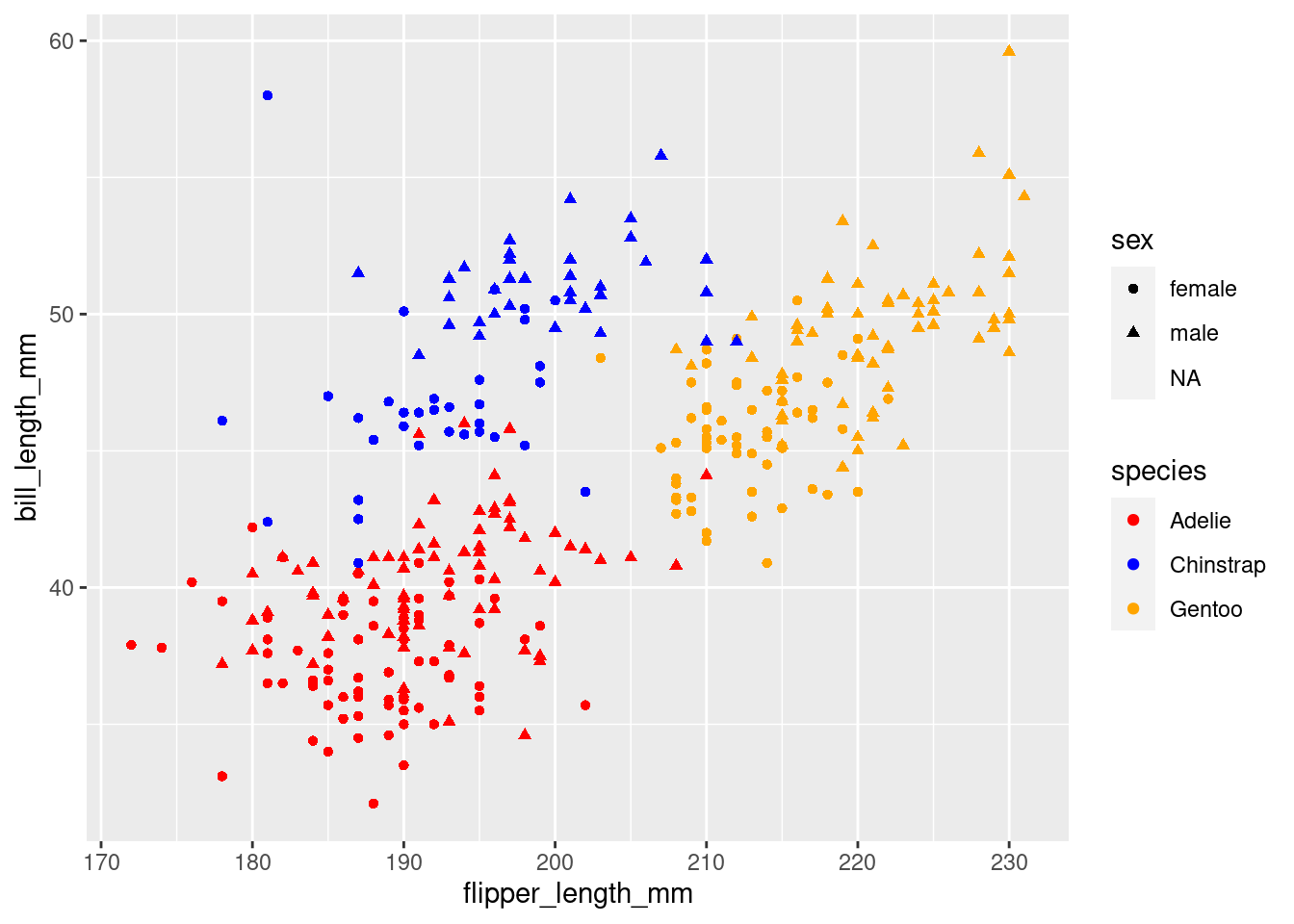
We can add or change labels (like the x-axis-label) by adding the labs function.
plt <- plt +
labs(x = "Flipper length [mm]",
y = "Bill length [mm]",
title = "Penguins!",
subtitle = "The 3 penguin species can differentiated by their flipper and bill lengths")The overall look of the plot is regulated by themes like the pre-made theme_ functions or more finely regulated with the theme() function, which uses element functions to create the look of individual elements. Autocomplete helps us out a lot here (Ctrl+Space).
plt <- plt +
theme_minimal() +
theme(legend.text = element_text(face = "bold"))
plt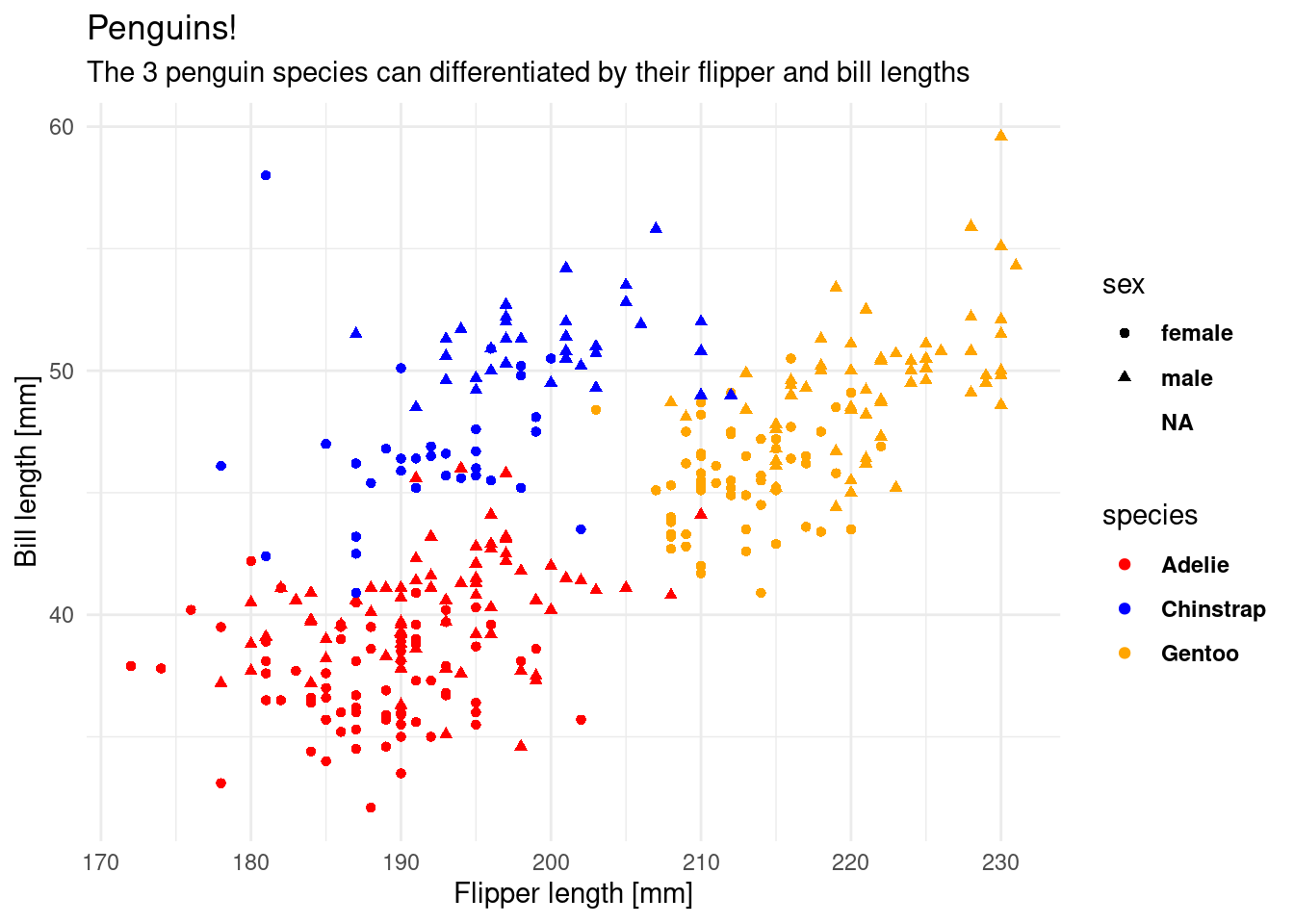
In summary, this is what our plot needs:
my_plot <- ggplot(penguins,
aes(x = flipper_length_mm,
y = bill_length_mm,
shape = sex,
color = species)) +
geom_point() +
scale_color_manual(values = c("red", "blue", "orange")) +
labs(title = "Penguins") +
theme(plot.title = element_text(colour = "purple"))
my_plot 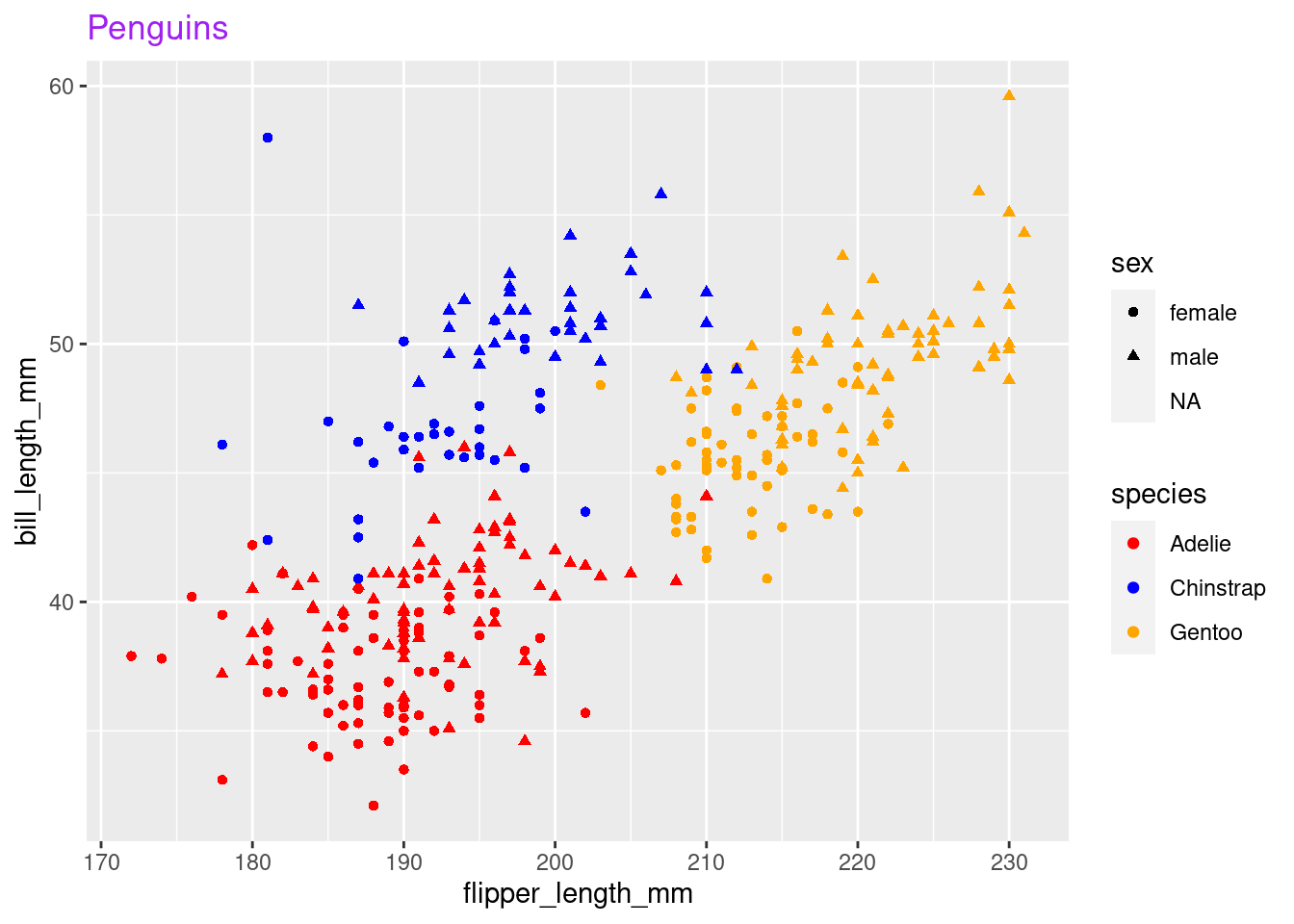
We can save our plot with the ggsave function. It also has more arguments to control the dimentions and resolution of the image.
ggsave("my_plot.png", my_plot)Next week we will be get rid of the annoying NA in the legend for sex.


This course is not graded, but I need some way of confirming that you did indeed take part in this course. In order to get the confirmation, you will send your solutions for a minimum of 6 out of the 8 exercises to me before the Seminar Tuesdays For each week I would like you to create a fresh quarto document with your solutions as code as well as any questions that arose during the lecture. This will help me a lot in improving this course.
When you are done solving the exercises, hit the knit button (at the top of the editor panel) and send me the resulting html document via discord (confirm that it looks the way you expected beforehand).
Here are today’s tasks:
In a fresh quarto document (without the example template content), load the tidyverse and the palmerpenguins packages.
Write a section of text about your previous experience with data analysis and/or programming (optional, but I can use this information to customize the seminars to your needs).
Create a vector of all odd numbers from 1 to 99 and store it in a variable.
tibble function. Remember that you can always access the help page for a function using the ? syntax, e.g. ?tibble::tibble (The two colons :: specify the package a function is coming from. You only need tibble(...) in the code because the tibble package is loaded automatically with the tidyverse. Here, I specify it directly to send you to the correct help page).tibble where the columns are the vectors x and y.ggplot.geom_ function do you need to add to the plot to add a line that connects your points?Load the penguins dataset from the palmerpenguins package. Produce a scatterplot of the bill length vs. the bill depth, colorcoded by species.
scale_color_manual() to find out how. Note, that R can work with it’s built-in color names, rgb() specifications or as hex-codes such as #1573c7). Even more bonus points if you also look into the theme() function and it’s arguments, or the theme_<...>() functions to make the plot prettier.Check the metadata (YAML) of your quarto document and make sure it contains your name as the author:.
The filename of your solution should also contain your name, e.g. lecture1-jannik.qmd, which gets rendered to lecture1-jannik.html when you knit it.
Make the output document self contained by adding embed-resources: true to the yaml header.
The top of your Quarto document should now look like this between the ---:
title: "Lecture 1"
author: <Your Name>
format:
html:
embed-resources: true
# more html options if you want
# like e.g. theme: <...>
execute:
warning: false.html, .png, docx). Here is a guide on how to turn them on in Windows 11 and 10. I recommend to to so, to make it easier for you to send the correct file (the rendered html file instead of the source qmd).Check out the dedicated Resources page.