install.packages("tidymodels")6 Distributions, Summaries and Dimensionality Reduction
… in which we explore continuous distributions with spotify data, find out about the central limit theorem and related statistical tests and become N-dimensional whale sharks.
As it turns out this lecture got quite long. So I separated two small interludes that are not crucial to the bigger picture out into a bonus video. You can recognize the corresponding parts of the script by a prefix of [Sidenote] in the section heading. They should be interesting to watch and read but are not required for the exercises.
Here is the main lecture video:
And here are the bonus bits:
6.1 Some Preparation
Today, we will explore the process of modeling and look at different types of models. In part, we will do so using the tidymodels framework. The tidymodels framework extends the tidyverse with specialized tools for all kinds of modeling tasks that fit neatly in with all the tools we already know. Go ahead and install them with:
Now we are ready to get started
library(tidyverse)
library(tidymodels)6.1.1 [Sidenote] on Reproducible Environments with renv
At this point, we have installed quite a lot of packages. On one hand, this is great fun because the extend what we can do and make tedious tasks fun. On the other hand, every package that we add introduces what is called a dependency. If a user doesn’t have the package installed, our analysis will not run. If we are feeling experimental and use functions from packages that are under active development and might change in the future, we will run into trouble when we update the package. But never updating anything ever again is no fun! I will show you, how to get the best of both worlds: All the packages and functions that your heart desires while maintaining complete reproducibility. This is to make sure that you can come back to your old projects 2 years from now and they still just run as they did at the time.
This solution is a package called renv. The idea is as follows: Instead of installing all your packages into one place, where you can only have one version of a package at a time, renv installs packages locally in your project folder. It also meticulously writes down the version numbers of all the packages you installed and keeps a cache, so it will not copy the same version twice.
It is an R package like any other, so first, we install it with:
install.packages("renv")Then, in our RStudio project in the R console, we initialize the project to use renv with:
renv::init()This does a couple of things. It creates a file named .Rprofile, in which it writes source("renv/activate.R"). The R-profile file is run automatically every time you start a R session in this folder, so it makes sure renv is active every time you open the project. It also creates a folder called renv. This is the where it will install packages you want to use in the project. The most important file is the renv.lock file. You can have a look at it, it is just a text file with all the packages and their exact versions.
You notice, that after initializing renv, we have no packages, so for example we can’t load the tidyverse as usual. We will have to install it again! However, in this case it should be fairly fast, because renv knows that it was already installed globally so it simply copies the files, which is fast. After having installed a new package, we call:
renv::snapshot()Renv tells us, what we changed in our environment and after we confirm, it notes down the changes.
Not it is also really easy to collaborate with other people. Because after we send them our project folder, all they have to do is run:
renv::restore()To install all packages noted down in the lockfile. We can also use this ourselves if we installed a few to many packages or did an update we regret and want to go back to what is written in the lockfile.
Finally, renv also provides functions to update or install new packages. They work like install.packages, but a bit more versatile. For example, let me show you the different locations from which we can install packages.
- The main location is CRAN (The Comprehensive R Archive Network). This is also from where you installed R itself. R packages on there are subject to certain standards and usually stable and tested.
- We can also install packages directly from the source code other people uploaded. GitHub is a platform where you can upload code and track changes to it. A lot of times, you can find the current developement version of an R package, or packages that are not yet on CRAN on GitHub.
renv can install packages from GitHub as well, for example let us say, we want to test out the latest version of the purrr package to give feedback to the developers.
https://github.com/tidyverse/purrr here it says:
# ...
# Or the the development version from GitHub:
# install.packages("devtools")
devtools::install_github("tidyverse/purrr")Well, we don’t need devtools for this, because renv can do this with the regular install function:
renv::install("tidyverse/purrr")Giving it just a package name installs a package from CRAN, a pattern of "username/packgename" installs from GitHub. Now, back to the actual topic of today!
After having initialized renv we need to install the packages that we need for the project even if we already have them in our global package cache, just so that renv knows about them.
6.2 All models are wrong, but some are useful
“All models are wrong, but some are useful” — George Box
What this means is that any model is but a simplification of reality and must always omit details. No model can depict the complete underlying reality. However, models are useful, and to understand what they are useful for, we must first look at the different types of models out there.
6.2.1 Types of Models
The tidymodels book names three types of models, where any particular model can fall into multiple categories at once:
- Descriptive Models are purely used to describe the underlying data to make patters easier to see. When we add a smooth line to a ggplot with
geom_smooth, the default method is a so called LOESS curve, which stands for Locally Estimated Scatterplot Smoothing. It does produce insights by revealing patterns to us, but by itself can not be used e.g. to make predictions. It is just a pretty looking smooth line.
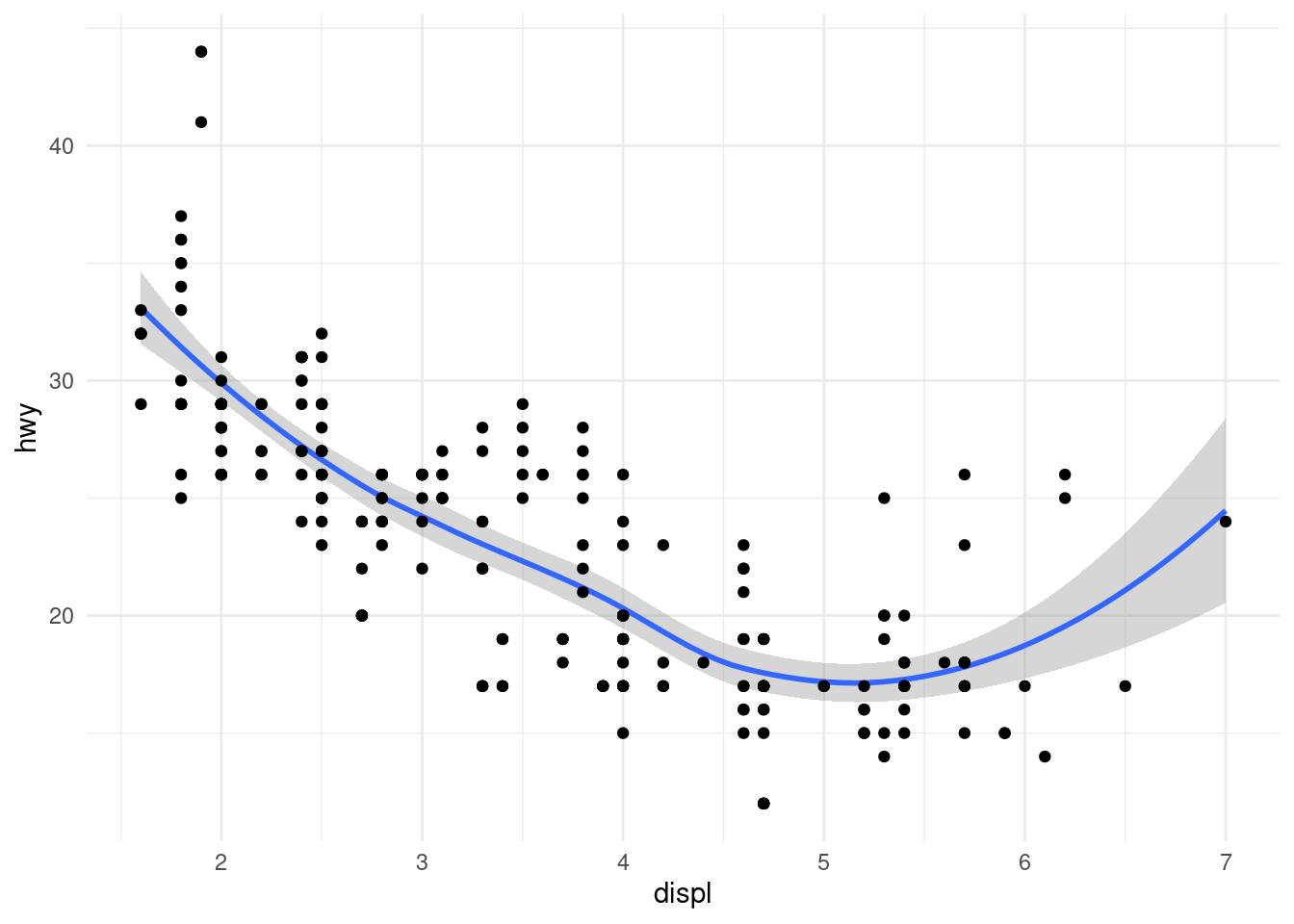
Inferential Models are designed to test hypothesis or make decisions. They rely heavily on our assumptions about the data (e.g. what probability distribution the populations follows) and will be most likely encountered by you to answer research questions. They are the models that typically produce a p-value, which you compare to a threshold like we did last week.
Predictive Models are designed to process the data we have and make predictions about some response variable upon receiving new data. When done correctly, we also hold out on some of the data that our model never gets to see, until it is time to evaluate and test how it performs on unseen data. Depending on how much we know (or want to know) about the underlying processes, we differentiate between mechanistic models like fitting a physically meaningful function to data and empirically driven models, which are mainly concerned with creating good predictions, no matter the underlying mechanism.
We will now explore different examples. First, let me introduce our dataset for today:
6.3 Say Hello to Spotify Data
I created a playlist on spotify, which is quite diverse so that we can look at a range of features. You can even listen to it here while you do the exercises if you want. I am doing so, as I write this. The cool thing about spotify is, that they have an API, an Application Interface. APIs are ways for computer programs to talk to each other. So while we use the spotify app to look up songs, computers use the API to talk to the spotify server. And because R has a rich ecosystem of packages, someone already wrote a package that allows R to talk to this API: spotifyr.
If you check out the R folder in this lecture, you can see how I downloaded and processed that data about the playlist. Note that the script will not work for you right away, because you first need to register with spotify as a developer and then get a so called token, like a username and password in one long text, to be allowed to send bots their way. You probably just want to download the data from my github repository.
Let’s have a look, shall we?
songs <- read_csv("data/06/spotify_playlist.csv")We can get a quick overview of all columns with:
glimpse(songs)Rows: 393
Columns: 18
$ track_name <chr> "Africa", "Take on Me", "Wake Me Up Before You Go-Go…
$ track_artists <chr> "TOTO", "a-ha", "Wham!", "Elton John", "The HU;Jacob…
$ danceability <dbl> 0.671, 0.573, 0.620, 0.504, 0.373, 0.624, 0.789, 0.7…
$ energy <dbl> 0.373, 0.902, 0.573, 0.904, 0.895, 0.857, 0.789, 0.6…
$ key <dbl> 9, 6, 0, 6, 8, 10, 2, 4, 4, 6, 6, 4, 4, 11, 10, 10, …
$ loudness <dbl> -18.064, -7.638, -11.893, -6.863, -3.846, -6.250, -4…
$ mode <dbl> 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1…
$ speechiness <dbl> 0.0323, 0.0540, 0.0423, 0.1790, 0.0610, 0.0542, 0.29…
$ acousticness <dbl> 0.257000, 0.018000, 0.271000, 0.356000, 0.022100, 0.…
$ instrumentalness <dbl> 8.01e-05, 1.25e-03, 0.00e+00, 1.21e-01, 2.45e-04, 2.…
$ liveness <dbl> 0.0481, 0.0928, 0.0607, 0.1400, 0.6610, 0.1100, 0.09…
$ valence <dbl> 0.7320, 0.8760, 0.8970, 0.7720, 0.6680, 0.3240, 0.37…
$ tempo <dbl> 92.718, 84.412, 81.548, 176.808, 172.392, 131.926, 1…
$ time_signature <dbl> 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4…
$ track_duration_ms <dbl> 295893, 225280, 231333, 183440, 317077, 282920, 2480…
$ track_popularity <dbl> 82, 84, 79, 80, 57, 60, 74, 84, 84, 82, 82, 81, 81, …
$ track_uri <chr> "spotify:track:2374M0fQpWi3dLnB54qaLX", "spotify:tra…
$ track_year <dbl> 1982, 1985, 1984, 1983, 2020, 2019, 2019, 2015, 2015…Finally some decent numbers! Not just these measly discrete values we had last week. For each song in the playlist, we get the artist, the year it arrived and a number of features like how danceable, how loud or fast the song is. You can easily imagine spotify using these numbers to suggest new songs based on the features of those that you have listened to. And in fact, we are going to lay the foundations for such an algorithm today.
6.4 Visualising Continuous Distributions
When dealing with a continuous distribution, like we have for a lot of our features in the spotify songs dataset, there are always multiple ways to represent the same data. First, we just look at the numbers. We will use the valence values for our songs:
head(songs$valence)[1] 0.732 0.876 0.897 0.772 0.668 0.324Notice anything interesting in the numbers? I don’t either. Our brain is way better suited for looking at graphical representations, so: To the ggplot cave!
songs %>%
ggplot(aes(x = "", y = valence)) +
geom_point()
This is kind of hard to see, because points overlap. We can get a better picture of the distribution by using transparency or a bit of jitter:
songs %>%
ggplot(aes(x = "", y = valence)) +
geom_jitter(width = 0.1)
Using a histogram, we can put the points into bins and get a plot similar to what we got for discrete values. Note that the plot is flipped on it’s side now.
songs %>%
ggplot(aes(valence)) +
geom_histogram()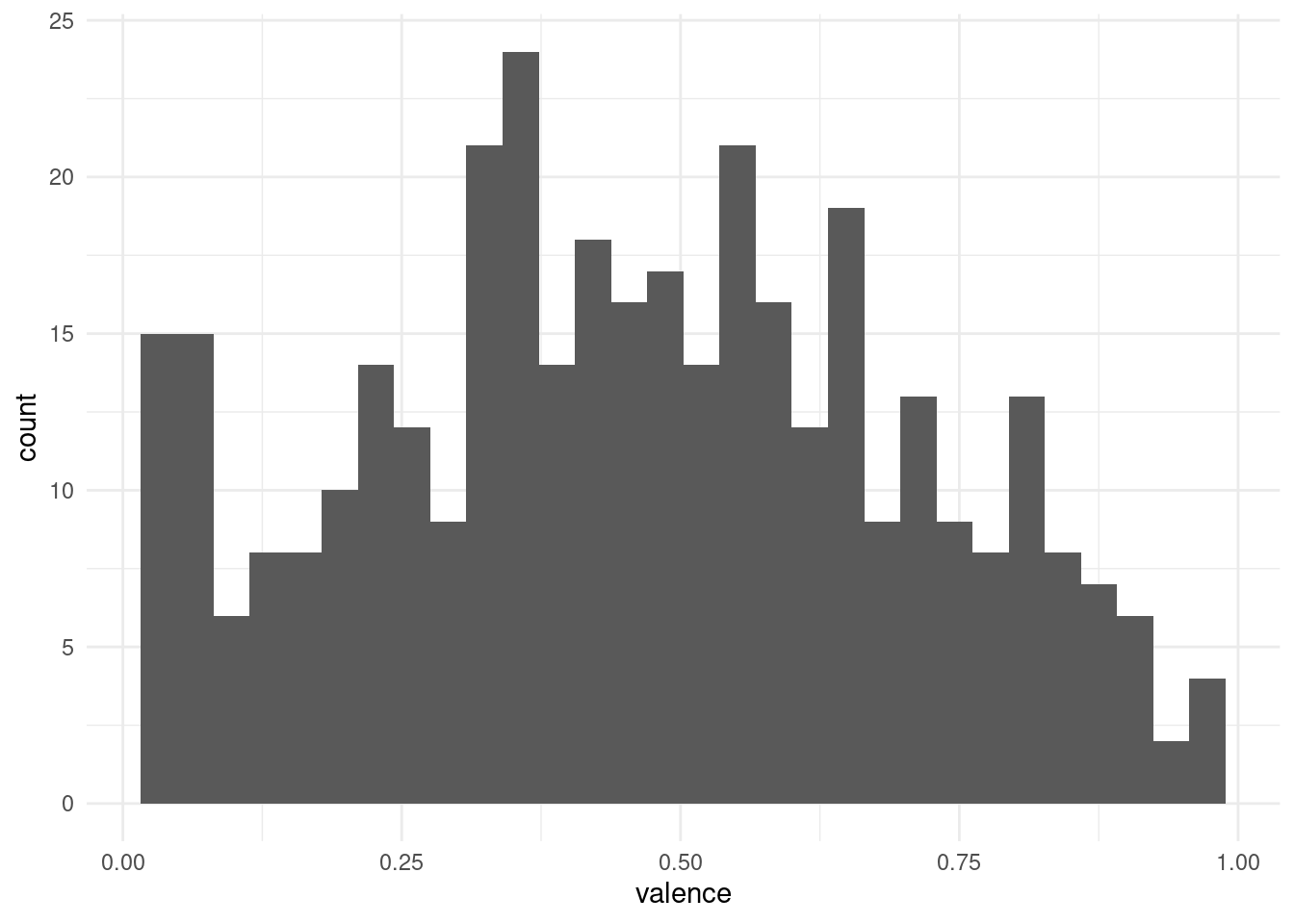
And we might want to play around with the bin size to get a better feel for the distribution. Another way is to apply a smoothing function and estimate the density of points along a continuous range, even in places where we originally had no points:
songs %>%
ggplot(aes(valence)) +
geom_density(fill = "midnightblue", alpha = 0.6)
Both of these plots can be misleading, if the original number of points is quite small, and in most cases, we are better off, showing the actual individual points as well. This is the reason, why the first plots I did where vertical, because there is a cool way of showing both the points and the distribution, while still having space to show multiple distributions next to each other. Imagine taking the density plot, turning it 90 degrees and then mirroring through the middle. What we get is a so called violin plot. To overlay the points on top, we will use something a little more predictable than jitter this time: From the ggbeeswarm package I present: geom_quasirandom.
songs %>%
ggplot(aes(x = "", y = valence)) +
geom_violin(fill = "midnightblue", alpha = 0.6) +
ggbeeswarm::geom_quasirandom(width = 0.35)
This is cool, because now we can easily compare two different distributions next to each other and still see all the individual points. For example, we might ask:
“Do songs in major cord have a higher valence than songs in minor cord in our dataset?”
songs %>%
filter(!is.na(mode), !is.na(valence)) %>%
ggplot(aes(x = factor(mode), y = valence)) +
geom_violin(fill = "midnightblue", alpha = 0.6) +
ggbeeswarm::geom_quasirandom(width = 0.35) +
scale_x_discrete(labels = c(`0` = "minor", `1` = "major"))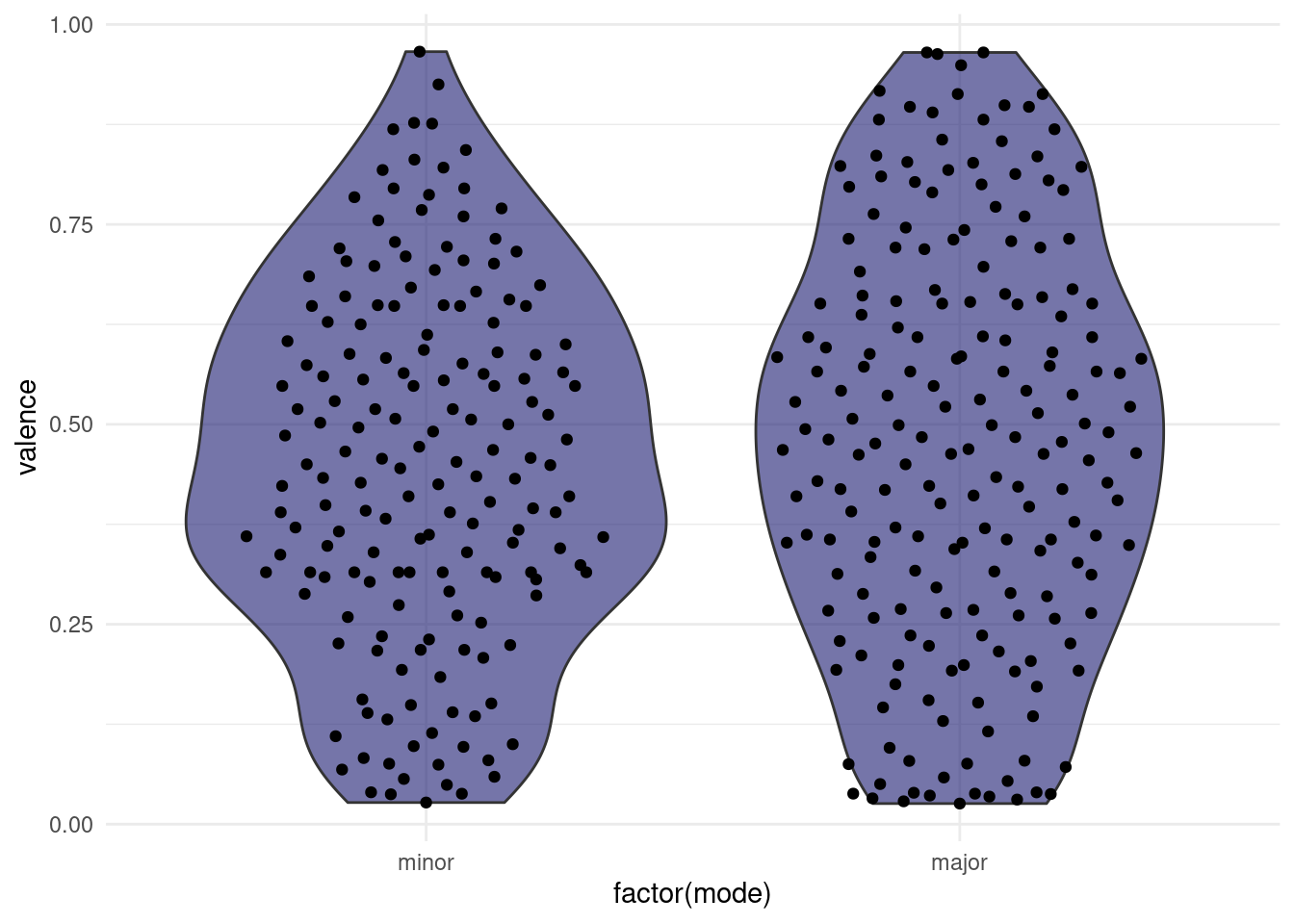
Note: This jittering only works, because the feature on the x-axis is discrete. If it where continuous, we would be changing the data by jittering on the x-axis.
We might also want to add summaries like the mean for each group to the plot with an additional marker. This leads us to the general concept of summary statistics. There is a number of them, and they can be quite useful to, well, summarise a complex distribution. But they can also be very misleading, as can any simplification be.
6.5 Summary Statistics…
6.6 Mean, Median (and other Quartiles), Range
Let us start by considering different things we can say about our distribution in one number. First, we might look at the range of our numbers, the maximum and minimum. We will do this per mode, so we can compare the values. Next, we want to know the centers of the points. There are different notions of being at the center of the distribution. The mean or average is the sum of all values divided by the number of values. The median is what we call a quantile, a point that divides a distribution in equally sized parts, specifically such that 50% values are below and 50% are above the median.
songs %>%
drop_na(valence, mode) %>%
group_by(mode) %>%
summarise(
min = min(valence),
max = max(valence),
mean = mean(valence),
median = median(valence)
)# A tibble: 2 × 5
mode min max mean median
<dbl> <dbl> <dbl> <dbl> <dbl>
1 0 0.0271 0.966 0.448 0.447
2 1 0.0258 0.965 0.475 0.477It appears the valence can assume values between 0 and 1. A shortcut for this is the range function:
range(songs$valence)[1] NA NAThe median is just one of the many percentiles we can think of. If we display the 50th as well as the 25th and 75th percentile on one plot, we get what is called a boxplot:
# in the lecture I used filter(!is.na(mode), !is.na(valence)),
# but drop_na is more elegant.
songs %>%
drop_na(valence, mode) %>%
ggplot(aes(x = factor(mode), y = valence)) +
geom_boxplot(fill = "midnightblue", alpha = 0.6, outlier.color = NA) +
ggbeeswarm::geom_quasirandom(width = 0.35) +
scale_x_discrete(labels = c(`0` = "minor", `1` = "major"))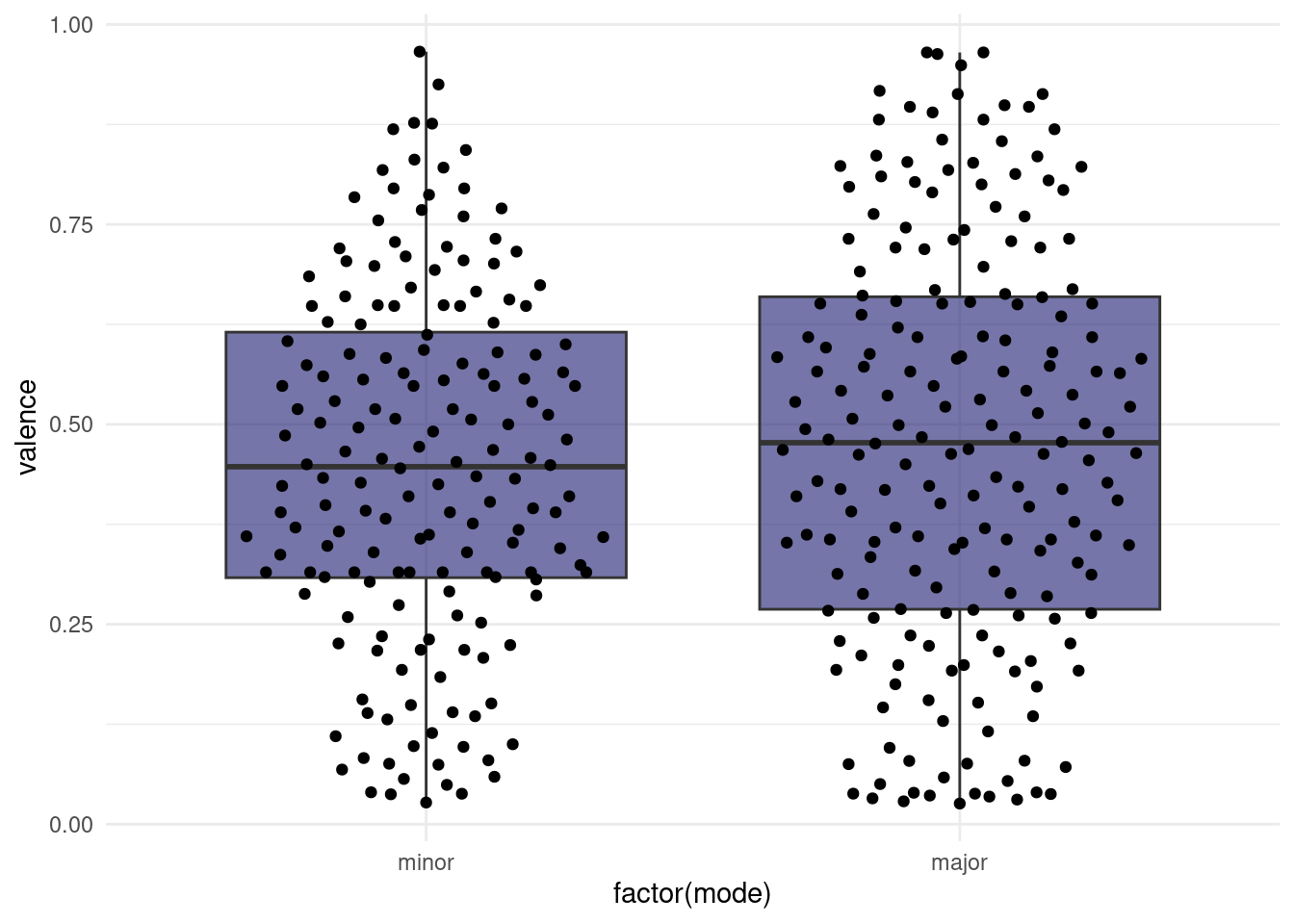
The “whiskers” of the box extend to 1.5 times the box size or to the last data point, whichever makes smaller whiskers. Points that are more extreme than the whiskers are labeled outliers by the boxplot and usually displayed as their own points. Like with the violin plot, we also have the option to plot the original un-summarized points on top. In this case, we need to make sure to change the outlier color for the boxplot to NA, because otherwise we are plotting them twice.
This hints at one downside of boxplots (when used without adding the raw datapoints as well): The box is a very prominent focus point of the plot, but by definition, it only contains 50% of all datapoints. The rest is delegated to thin whiskers.
6.6.1 Variance
Finally, we want to know, how far the values scatter around their means and the potential population mean. This is encompassed in two closely related measures: the variance and the standard deviation.
For illustrative purposes, we can plot all datapoints for e.g the valence in the order in which they appear in the data and add a line for the mean.
songs %>%
filter(!is.na(valence)) %>%
mutate(index = 1:n()) %>%
ggplot(aes(index, valence)) +
geom_segment(aes(y = mean(valence),
yend = mean(valence),
x = 0,
xend = length(valence))) +
geom_segment(aes(xend = index, yend = mean(valence)),
color = "darkred", alpha = 0.6) +
annotate(x = length(songs$valence),
y = mean(songs$valence, na.rm = TRUE),
label = "Mean",
geom = "text") +
geom_point()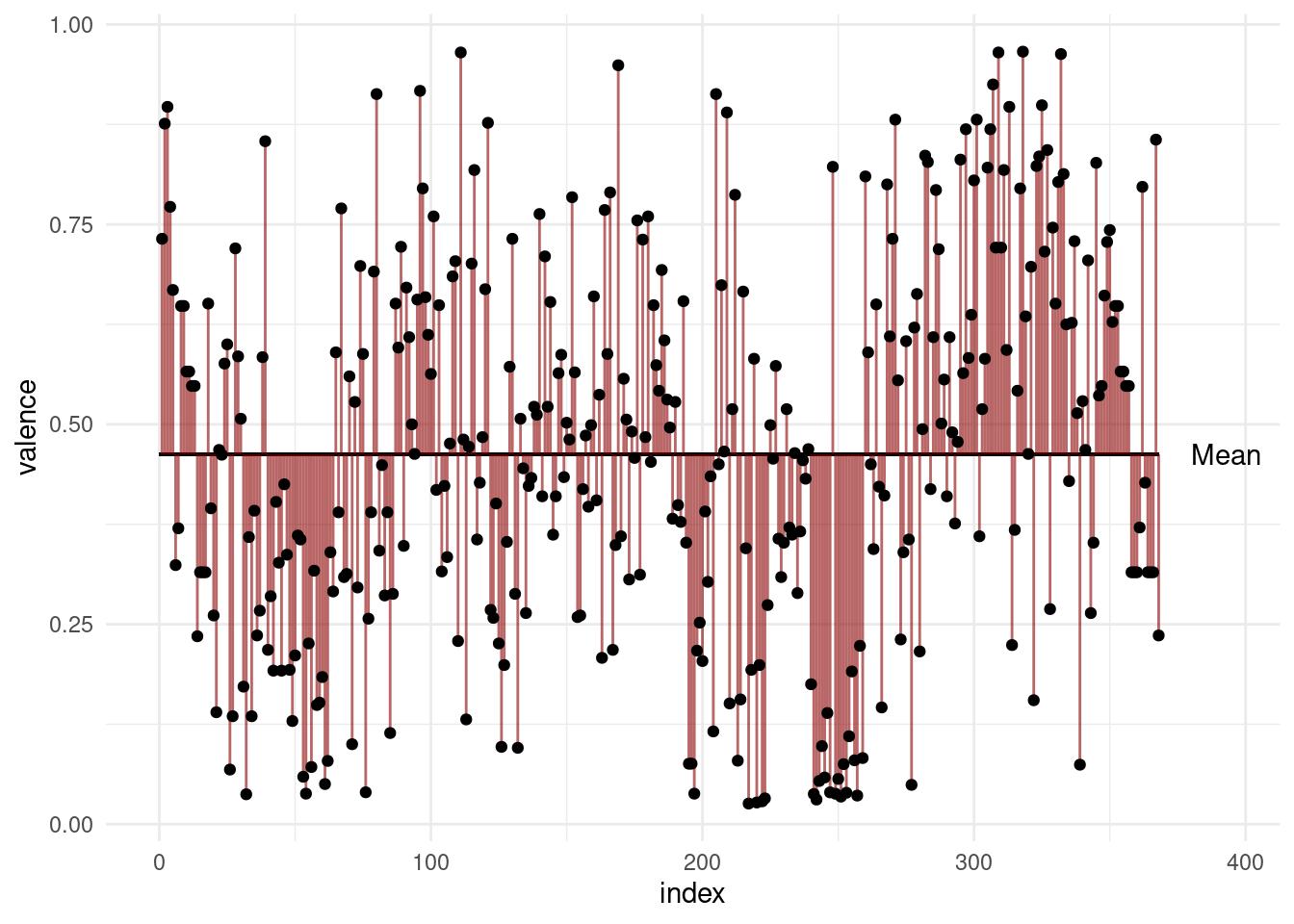
The variance is the expected value of the squared deviation of a random variable from its mean.
In other words: Take the distance of all points to the mean and sum them (add all red lines in the plot above together) and then divide by \(n-1\).
\[var(X) = \frac{\sum_{i=0}^{n}{(x_i-\bar x)^2}}{(n-1)}\]
“Hang on!”, I hear you saying: “Why \(n-1\)?”. And it is an excellent question. The first statement talked about an expected value. (One example of an expected value is the mean, which is the expected value of… well, the values). And indeed, and expected value often has the term \(1/n\). But the statement was talking about the expected value (of the squared deviation) for the whole population. We can only use the uncorrected version when we have the whole population (e.g. all songs that ever existed) and want to talk about that population. But usually, all we have is a sample, from which we want to draw conclusions about the population. But when we are using the sample to estimate the variance of the population, it will be biased. We can correct for this bias by using \(n-1\) instead of \(n\). This is known as Bessel’s correction. I am yet to come by a really intuitive explanation, but here is one idea: The thing we are dividing by is not necessarily the sample size any time we want to try to calculate the expected value of an estimator, it just happens to be the sample size in a bunch of cases. What the term really represents here is the degrees of freedom (DF) of the deviations. DFs can be thought of as the number of independent things. The degrees of freedom are \(n\) reduced by \(1\), because if we know the mean of a sample (we use it in our calculation), once we know all but \(1\) of the individual values, the last value is automatically known and thus doesn’t count towards the degrees of freedom.
6.6.2 Standard deviation
Next up: The Standard Deviation (SD) is the square root of the variance. Which is more commonly used on error bars, because the square root inverts the squaring that was done to get the variance. So we are back in the dimensions of the data.
\[\sigma_X=\sqrt{var(X)}\]
6.6.3 Standard Error of the Mean
Finally, we have the Standard Error of the Mean, sometimes only called Standard Error (SEM, SE). It is also used very commonly in error bars. The reason for a lot of people to favor it over the SD might just be, that it is smaller, but they have distinct use-cases.
\[SEM=\sigma / \sqrt{n}\]
We take the standard deviation and divide it by the square-root of \(n\). Imagine this: We actually have the whole population available. Like for example all penguins on earth. And then we repeatedly take samples of size \(n\). The means of these individual samples will vary, so it will have it’s own mean, standard deviation and variance. The standard error is the standard deviation of these means. So it is a measure of how far the means of repeated samples scatter around the true population mean. However, we don’t usually have the whole population! Measuring some property of all penguins in the world takes a long time, and running an experiment in the lab for all cells that exist and will ever exist takes an infinite amount of time. This is probably more than our research grant money can finance. So, instead, the Standard Error of the Mean used the standard deviation of our sample in the formula above. It is our best estimate for the standard deviation of the whole population. So, when you are trying so make inferences about the mean of the whole population based on your sample, it makes sense to also give the SEM as a way of quantifying the uncertainty.
While R has functions for sd, mean and var, there is not built in function for the sem, but we can easily write one ourselves:
sem <- function(x) sd(x) / sqrt(length(x))songs %>%
drop_na(mode, valence) %>%
group_by(mode) %>%
summarise(
mean = mean(valence),
var = var(valence),
sd = sd(valence),
sem = sem(valence)
)# A tibble: 2 × 5
mode mean var sd sem
<dbl> <dbl> <dbl> <dbl> <dbl>
1 0 0.448 0.0498 0.223 0.0170
2 1 0.475 0.0653 0.255 0.01826.7 … or: How to Lie with Graphs
However, be very wary of simple bar graphs with error bars; there is a lot that can be misleading about them.
songs %>%
drop_na(speechiness, mode) %>%
group_by(mode) %>%
summarise(across(speechiness, list(m = mean, sd = sd, sem = sem))) %>%
ggplot(aes(factor(mode), speechiness_m, fill = factor(mode))) +
geom_errorbar(aes(ymin = speechiness_m - speechiness_sem,
ymax = speechiness_m + speechiness_sem,
color = factor(mode)),
size = 1.3, width = 0.3, show.legend = FALSE) +
geom_col(size = 1.3, show.legend = FALSE) +
coord_cartesian(ylim = c(0.06, 0.08)) +
scale_fill_manual(values = c("#1f6293", "#323232")) +
scale_color_manual(values = c("#1f6293", "#323232")) +
labs(title = "Don't Do This at Home!",
y = "Speechiness",
x = "Mode (Minor / Major)") +
theme(
plot.title = element_text(size = 44, family = "Daubmark",
color = "darkred")
)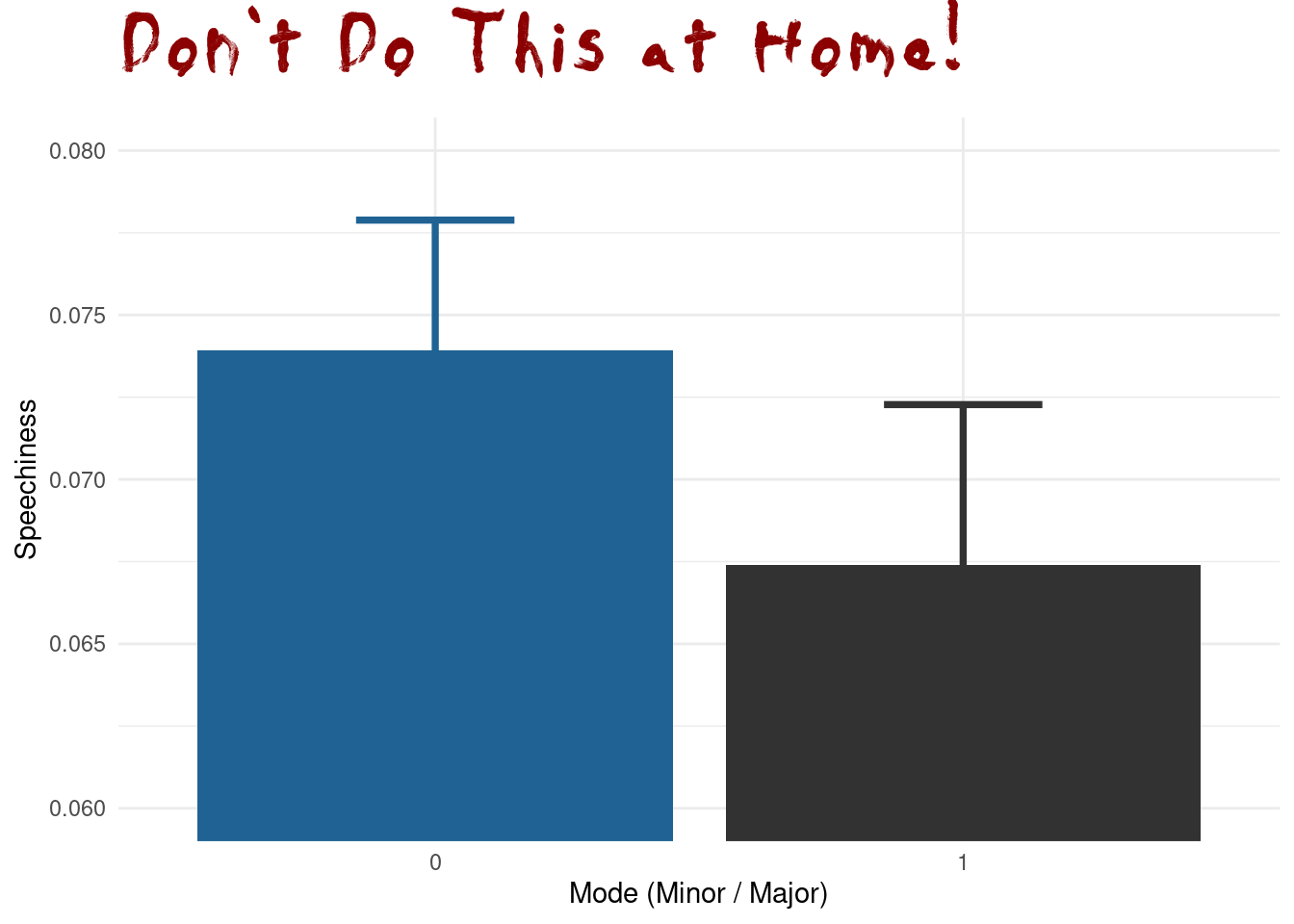
When people say “The y-axis has to include 0”, this is the reason for it. It is no always true, when there is another sensible baseline that is not 0, but especially for barplots not having the y-axis start at 0 is about the most misleading thing you can do. The main reason for this is that humans perceive the height of the bars via their area, and this is no longer proportional when the bars don’t start at 0. This plot also makes no indication of the type of error-bars used or the sample size in each group. It uses the speechiness feature, but it hides the actual distribution behind just 2 numbers (mean and SEM) per group.
songs %>%
ggplot(aes(speechiness, color = factor(mode), fill = factor(mode))) +
geom_density(alpha = 0.3)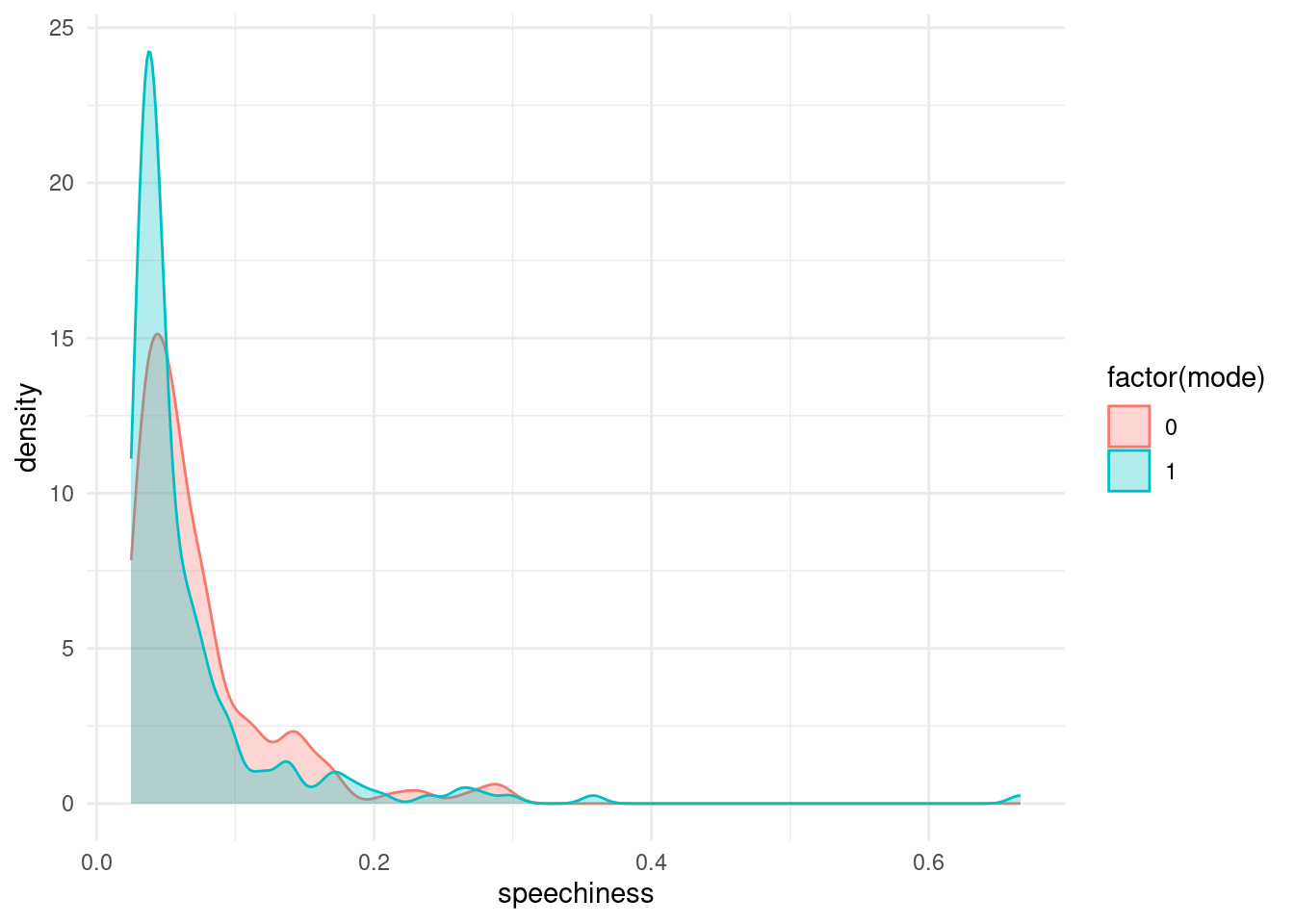
So the next time you see a barplot ask the question:

I hope you can take some inspiration from this chapter and now have the vocabulary to know where to look when it comes to your own data.
6.8 Graphic Devices, Fonts and the ggplot Book
6.8.1 ggplot book
Firstly, for all things ggplot, the third edition of the ggplot book is currently being worked on by three absolute legends of their craft (“Welcome | Ggplot2,” n.d.; Wickham 2016). Hadley Wickham is the author of the original ggplot and ggplot2 package, Danielle Navaro makes amazing artwork with and teaches ggplot and Thomas Lin Pedersen is the current maintainer of ggplot2 and constantly makes cool features for it. The under-development book is already available online for free: https://ggplot2-book.org/.
6.8.2 [Sidenote] Graphics Devices
Secondly, we need to briefly talk about a concept we have only brushed by: graphics devices are to R what your printer is to your computer. When we create a plot in R, it starts out as mere numbers, but something has to turn these numbers into pixels (in the case of raster-images) or vectors (in the case of vector images; you might know svg or pdf files. Sorry, but these are not the vectors in R but rather descriptions of lines). This is the job ob the graphics device. When we use the ggsave function for example, it figures out what to use based on the file extension, but we can also specify it manually. I am mentioning this here, because in the plot I just showed you, I used a different font than the default. This is something that can be incredibly tricky for graphics devices, because fonts are handled differently on every operating system. Luckily, it is about to get way easier, because Thomas Lin Pedersen is working on another package, a graphics device, that is both really fast and works well with fonts. You can check the current development version here: https://ragg.r-lib.org/
Here are some examples of using graphics devices manually by opening the device first and then finalizing the plot by closing the device:
png("myplot.png")
songs %>%
ggplot(aes(speechiness, color = factor(mode), fill = factor(mode))) +
geom_density(alpha = 0.3)
dev.off()svg("myplot.svg")
songs %>%
ggplot(aes(speechiness, color = factor(mode), fill = factor(mode))) +
geom_density(alpha = 0.3)
dev.off()Or by manually specifying the device in ggsave.
plt <- songs %>%
ggplot(aes(speechiness, color = factor(mode), fill = factor(mode))) +
geom_density(alpha = 0.3)
ggsave("newplot.png", plt, device = ragg::agg_png)6.9 The Normal Distribution and the Central Limit Theorem
There are many different distributions out there. Luckily, one of them is quite special and can be used in a multitude of settings. It is the harmlessly named Normal Distribution. R has the usual functions for it (density, probability, quantile, random).
tibble(x = seq(-3, 3, 0.01)) %>%
ggplot(aes(x)) +
geom_function(fun = dnorm) +
stat_function(geom = "area", fun = dnorm,
fill = "darkblue", alpha = 0.3) +
labs(y = "density", title = "Normal Distribution Density")
tibble(x = seq(-3, 3, 0.01)) %>%
ggplot(aes(x)) +
geom_function(fun = pnorm) +
labs(y = "probability", title = "Cummulative Probability")
Now, why is is distribution so special?
The Central Limit Theorem (CLT) states that the sample mean of a sufficiently large number of independent random variables is approximately normally distributed. The larger the sample, the better the approximation.
For a great visualization of the central limit theorem, check out this interactive tutorial by Seeing Theory.
Because a lot of values we measure are actually the sum of many random processes, distributions of things we measure can often be approximated with a normal distribution.
We can visually test if some values follow the normal distribution by using a quantile-quantile plot, which plots the quantiles of our sample against where the quantiles should be on the normal distribution. A straight line means it is perfectly normal.
qqnorm(songs$valence)
qqline(songs$valence, col = "red")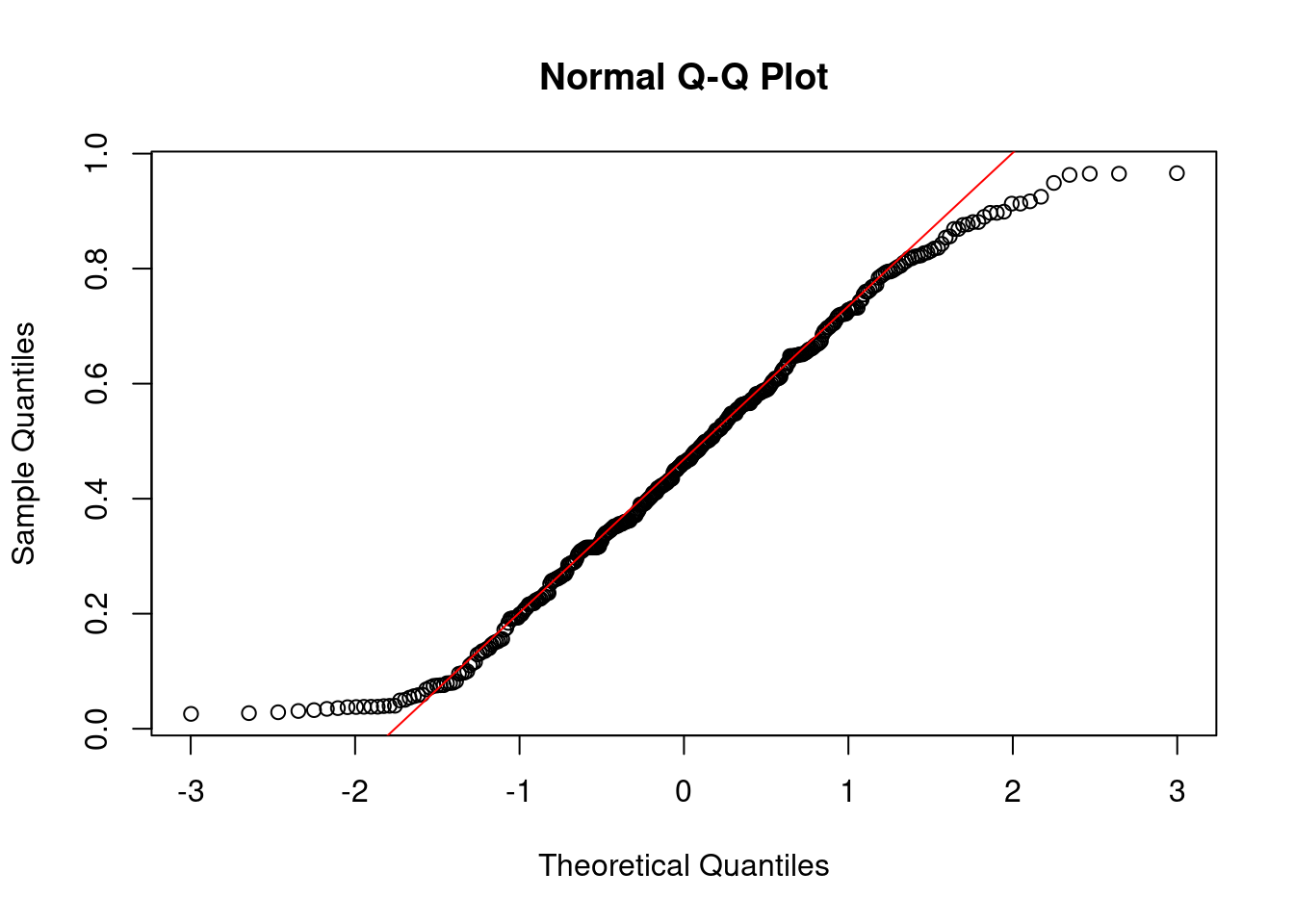
The values close to the mean are pretty normal, but the tails of the distribution stray further from the normal distribution. There are way more very small and very large values than would be expected from a normal distribution.
6.9.1 Log-normality
There is one thing that comes up a lot in biological data: because a lot of processes in biology are reliant on signal cascades, they tend to be the result of many multiplicative effects, rather than additive effects, as would be required for the Central Limit Theorem. As a result, they are not distributed normally, but rather log-normally, because taking the logarithm of all values transforms multiplicative effects into additive effects!
6.10 The T-Distribution
The CLT is only valid for large sample sizes. For smaller sample sizes, the distribution of means has fatter tails than a normal distribution. This is why for most statistical tests, we use the t-distribution instead of the normal distribution. As the degrees of freedom get higher, the t-distribution approaches the normal distribution.
base <- ggplot() + xlim(-5, 5)
base +
geom_function(aes(colour = "t, df = 1"), fun = dt, args = list(df = 1), size = 1.2) +
geom_function(aes(colour = "t, df = 3"), fun = dt, args = list(df = 3), size = 1.2) +
geom_function(aes(colour = "t, df = 30"), fun = dt, args = list(df = 30), size = 1.2) +
geom_function(aes(colour = "normal"), fun = dnorm, size = 1.2) +
guides(color = guide_legend(title = "")) +
scale_color_viridis_d()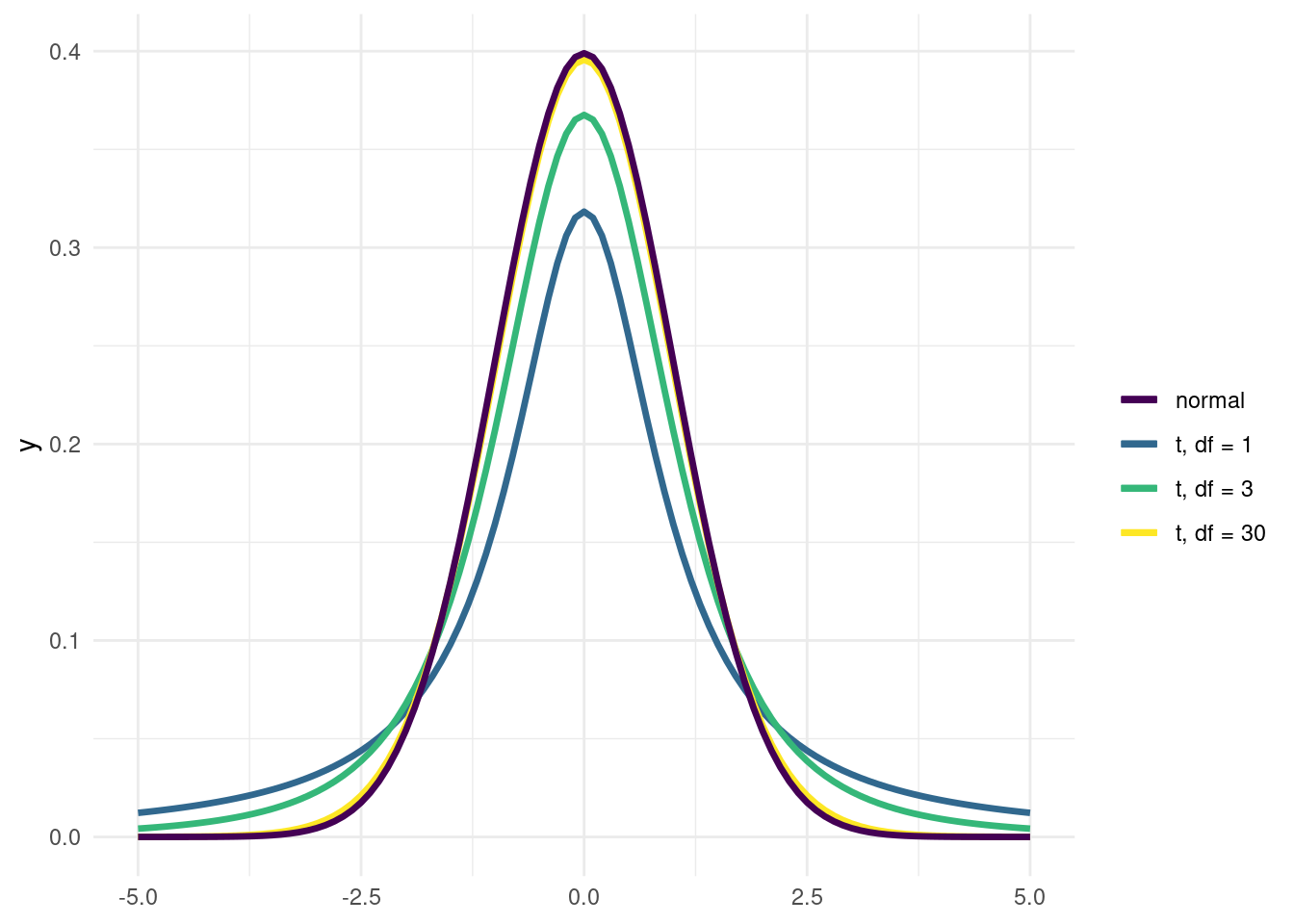
Remember the valence plot by mode?
songs %>%
ggplot(aes(factor(mode), valence)) +
geom_violin(fill = "darkblue", alpha = 0.3) +
ggbeeswarm::geom_quasirandom(alpha = 0.6)
For our purposes we are going to treat these two distributions as close enough to a normal distribution at first so that we can look at some hypothesis tests:
6.11 Student’s T-Test
The first test is called student’s t-test. “Student” was the pseudonym of it’s inventor. And the “t” stands for the t-distribution. We can use it to test the null hypothesis, that two samples come from the same (approximately normal) distribution.
t.test(valence ~ mode, data = songs)
Welch Two Sample t-test
data: valence by mode
t = -1.0857, df = 365.99, p-value = 0.2783
alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
95 percent confidence interval:
-0.07614235 0.02197185
sample estimates:
mean in group 0 mean in group 1
0.4480163 0.4751015 The two samples are so similar that is is quite likely for those values to have come form the same distribution, so we would not reject the null hypothesis.
Let us pretend for a moment that there is in fact a difference by creating some fake data (don’t do this in the lab…).
fake_songs <- songs %>%
drop_na(mode, valence) %>%
mutate(valence = if_else(mode == 1, valence + 0.2, valence))fake_songs %>%
ggplot(aes(valence, color = factor(mode), fill = factor(mode))) +
geom_density(alpha = 0.3)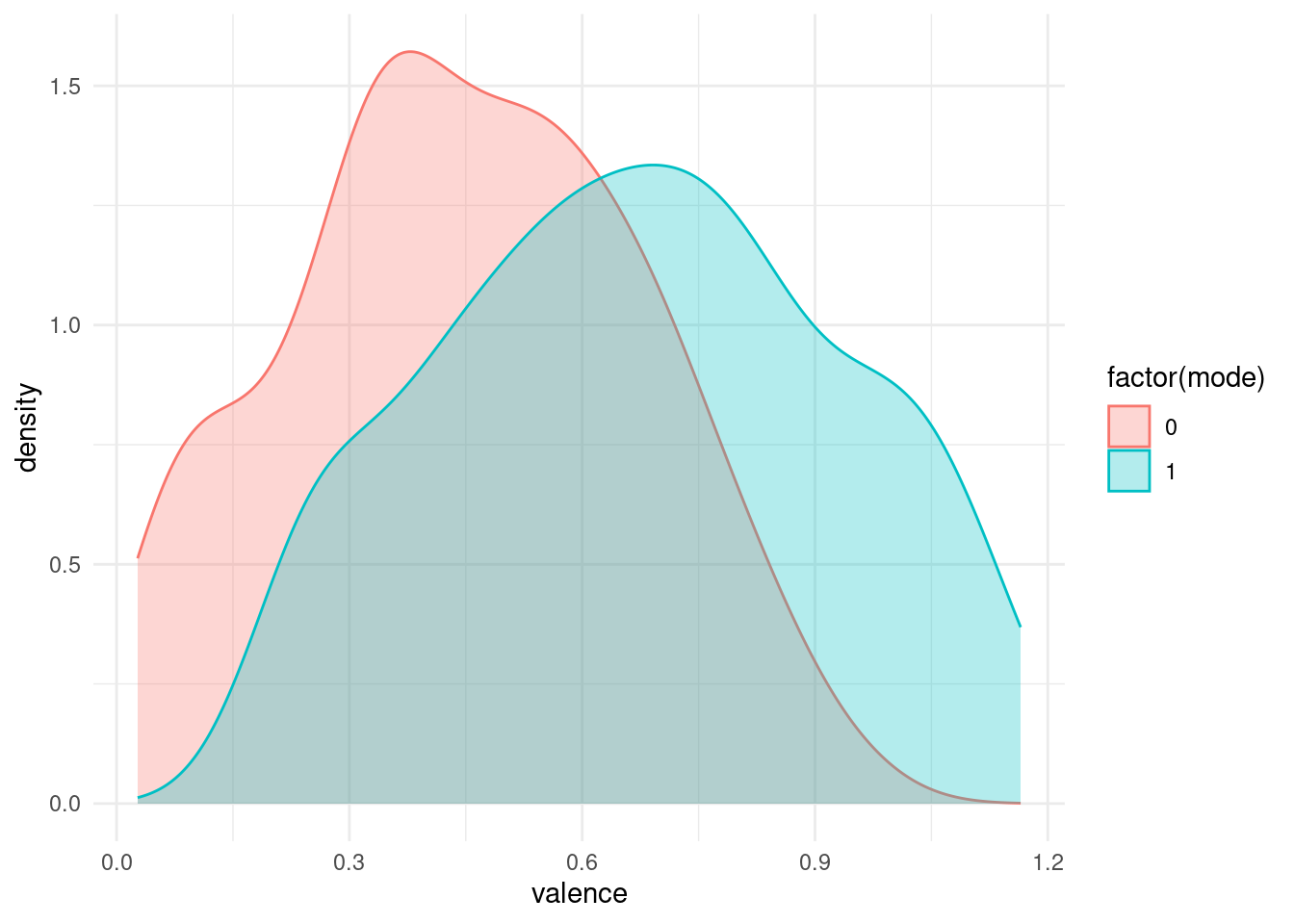
Now we end up with a statistically significant p-value.
t.test(valence ~ mode, data = fake_songs)
Welch Two Sample t-test
data: valence by mode
t = -9.1028, df = 365.99, p-value < 2.2e-16
alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
95 percent confidence interval:
-0.2761424 -0.1780282
sample estimates:
mean in group 0 mean in group 1
0.4480163 0.6751015 Note, that the p-value itself says nothing about the effect size, the difference in means between the sample. You can get a significant p-value either by showing a tiny difference with lot’s of data points or by showing a larger difference with less data points.
Tests, that rely on the assumption of normality are called parametric tests, but when this assumption can not be met, we need non-parametric tests.
6.12 Wilcoxon rank-sum test
The Wilcoxon rank-sum test, or Mann–Whitney U test, is one of these. I get’s around the assumption of normality by transforming the data into ranks first. i.e. all points (independent of group) are ordered and their values replaced by their position in the ordering (their rank). If we think of the t-test as testing for a difference in means, we can think of the Wilcoxon rank-sum test as testing for a difference in medians.
x <- c(1, 3, 2, 42, 5, 1000)
x[1] 1 3 2 42 5 1000rank(x)[1] 1 3 2 5 4 6wilcox.test(valence ~ mode, data = songs)
Wilcoxon rank sum test with continuity correction
data: valence by mode
W = 15834, p-value = 0.3155
alternative hypothesis: true location shift is not equal to 06.12.1 Direction of Testing
Both tests have the argument alternative, which can be any of c("two.sided", "less", "greater"). This is the direction of our alternative hypothesis. Are we testing, for x being greater or less than y? Or are we testing for a difference in any direction (the default)? Having a hypothesis about the direction beforehand will result in smaller p-values (half of the two-sided ones), but you need to have this hypothesis before looking at the data, and especially not after running e.g. the two sided test and then deciding, that you want a smaller p-value! This is not how p-values work.
t.test(valence ~ mode, data = fake_songs, alternative = "less")
Welch Two Sample t-test
data: valence by mode
t = -9.1028, df = 365.99, p-value < 2.2e-16
alternative hypothesis: true difference in means between group 0 and group 1 is less than 0
95 percent confidence interval:
-Inf -0.1859473
sample estimates:
mean in group 0 mean in group 1
0.4480163 0.6751015 fake_songs %>%
ggplot(aes(valence, color = factor(mode), fill = factor(mode))) +
geom_density(alpha = 0.3)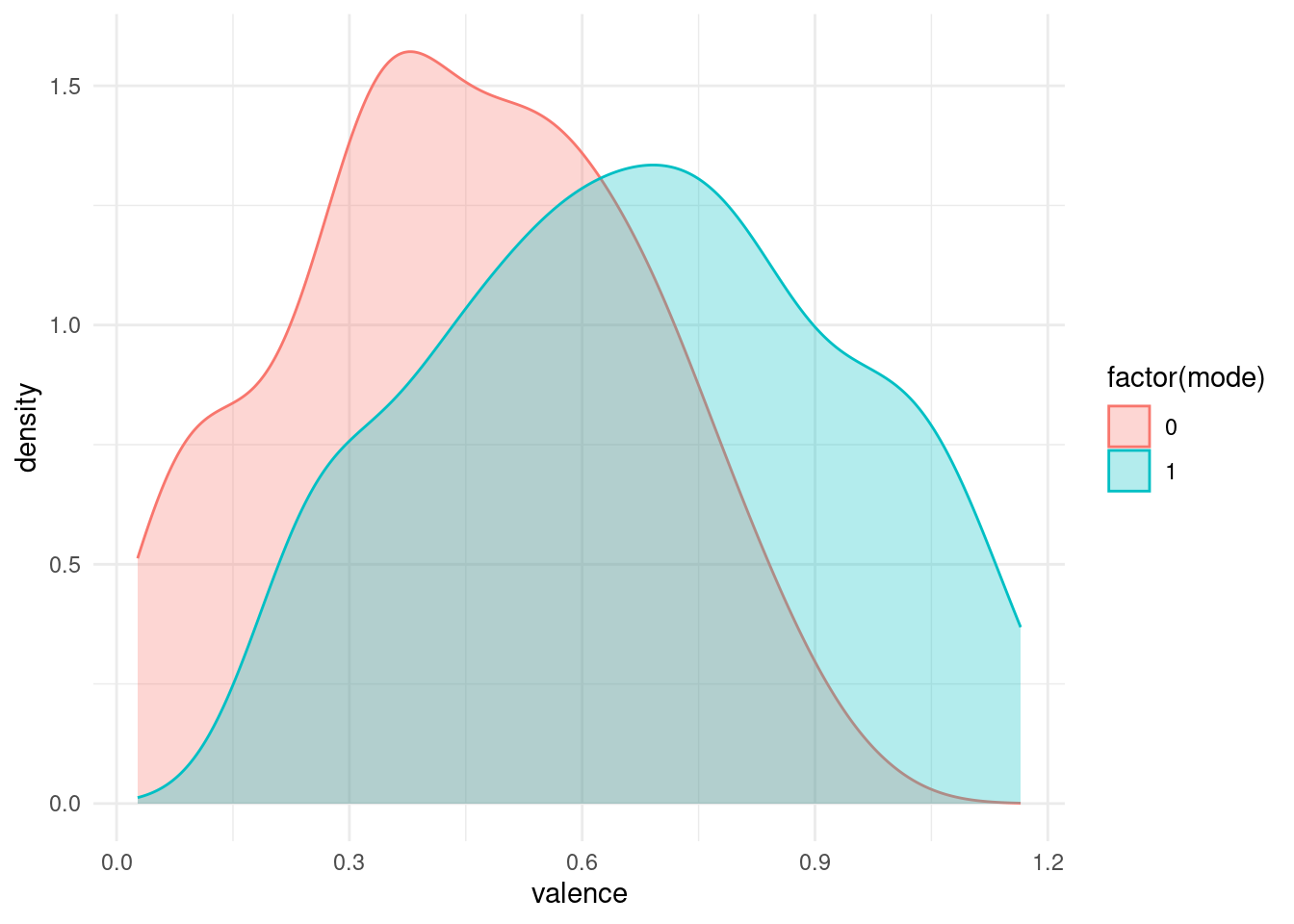
If you are unsure about how to tell the functions, which of two groups is supposed to be greater or lesser, you can also supply the data as x and y instead of using the formula interface as I did above:
valence_major <- fake_songs %>% filter(mode == 1) %>% pull(valence)
valence_minor <- fake_songs %>% filter(mode == 0) %>% pull(valence)
t.test(valence_major, valence_minor, alternative = "greater")
Welch Two Sample t-test
data: valence_major and valence_minor
t = 9.1028, df = 365.99, p-value < 2.2e-16
alternative hypothesis: true difference in means is greater than 0
95 percent confidence interval:
0.1859473 Inf
sample estimates:
mean of x mean of y
0.6751015 0.4480163 If we save the result of the test, we can inspect the object further and extract information from it.
test <- t.test(valence_major, valence_minor, alternative = "greater")
test$p.value[1] 2.893211e-186.12.2 Confidence Intervals
The t.test on a lonely sample can also be used to create confidence intervals around a mean. In short for example a 95% confidence interval is the range in which we would expect the mean of a sample to fall in 95% of cases when we repeat an experiment an infinite amount of times. These confidence intervals are also sometimes used as error bars in plots.
test <- t.test(songs$valence)
test$conf.int[1] 0.4377443 0.4871400
attr(,"conf.level")
[1] 0.956.13 Chrunching Dimensions with Dimensionality Reduction: PCA
Lastly for today, we are going a bit out of scope. We are leaving the realm of looking at individual features and try to condense all the information into as little space as possible.
The general notion of Dimensionality Reduction is to take all the features that we have and construct new features from them, so that we can represent our data with fewer features while loosing little information.
For example, when two features are highly correlated i.e. one changes when the other does, we might be better off replacing them with a single new feature, that goes along the axis of maximum variance between the two. A number along this line accounts for most of the variance in these points, and the rest can be accounted for by a number describing the distance to that line (a perpendicular axis), which is less important than the first axis we found.
songs %>%
ggplot(aes(x = energy,
y = loudness,
label = track_name)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE)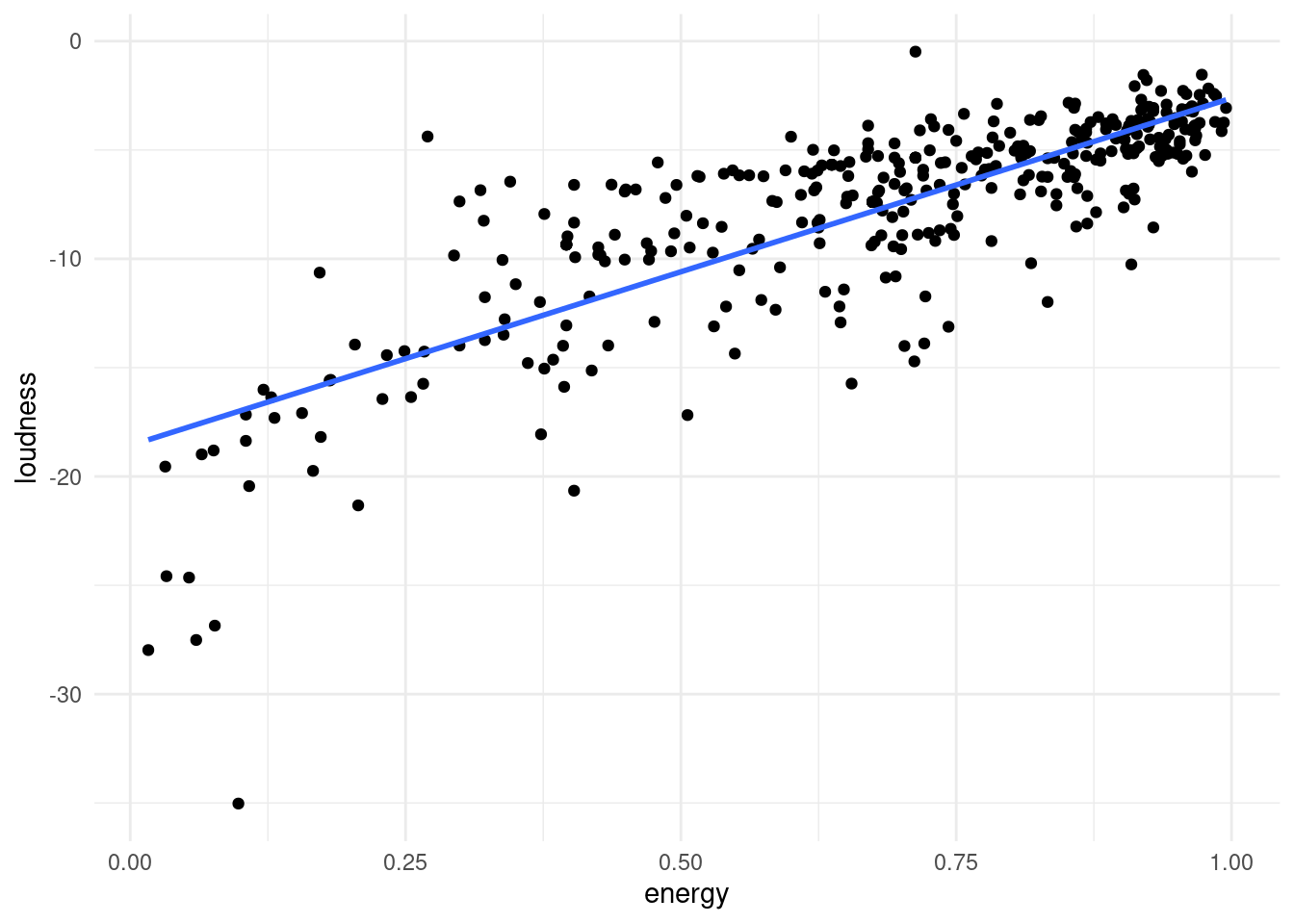
Imagine you are whale shark!

And want to orient your mouth in such a way that you can eat the greatest amount of krill in one sweep.

This is your first principal component. The second is perpendicular to the first. This is a throwback to “Math for Natural Scientists” and linear algebra, we are defining a new coordinate system here.
But whale sharks swim in 3 dimensions, not 2, and our data has even more dimensions, with features being represented dimensions.
It can be quite hard for humans to imaging being an N-dimensional whale shark.
But R and tidymodels has us covered.
PCA is not a model in itself, but rather a data preprocessing step that generates new features (the principal components), which we can later use for other models. But today, we will do just the preprocessing by itself.
In tidymodels, preprocessing is done by defining a recipe:
songs_rec <- recipe( ~ ., data = songs) %>%
update_role(track_name, track_artists, track_uri, new_role = "id variable") %>%
step_naomit(all_predictors()) %>%
step_normalize(all_predictors()) %>%
step_pca(all_predictors(), id = "pca")
songs_recWe then take the recipe and prepare it.
songs_prep <- prep(songs_rec)
songs_prepWe can now explore, how the data looks like in these new dimensions. We do so, by baking the prepared recipe.
songs_baked <- bake(songs_prep, songs)
songs_baked# A tibble: 393 × 8
track_name track_artists track_uri PC1 PC2 PC3 PC4 PC5
<fct> <fct> <fct> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Africa TOTO spotify:… 1.21 -3.32 -0.808 0.0396 0.811
2 Take on Me a-ha spotify:… -1.43 -1.84 -0.680 -0.400 0.376
3 Wake Me Up Bef… Wham! spotify:… 0.257 -3.23 0.397 0.242 -1.09
4 I'm Still Stan… Elton John spotify:… -1.08 -1.21 1.61 1.76 1.24
5 Wolf Totem (fe… The HU;Jacob… spotify:… -1.71 1.26 2.24 -1.74 1.47
6 Yuve Yuve Yu The HU spotify:… -0.774 0.792 -1.31 -0.446 0.743
7 The Search NF spotify:… -0.826 -0.511 -0.0294 2.62 -0.0331
8 Stressed Out Twenty One P… spotify:… -1.78 -0.647 -0.506 1.66 0.734
9 Stressed Out Twenty One P… spotify:… -1.78 -0.647 -0.506 1.66 0.734
10 Ride Twenty One P… spotify:… -1.08 -1.23 -0.907 -0.507 -1.22
# ℹ 383 more rowsThe original features where replace by Principal Components that explain most of the variance. From the prepared recipe, we extract a tidy form of the step we care about (usually the last one) to see, what happened to our data. We can see, which features ended up contributing to which components by getting the results of the pca step of our recipe.
terms <- tidy(songs_prep, id = "pca") %>%
mutate(component = parse_number(component))
terms# A tibble: 225 × 4
terms value component id
<chr> <dbl> <dbl> <chr>
1 danceability -0.226 1 pca
2 energy -0.423 1 pca
3 key -0.0765 1 pca
4 loudness -0.429 1 pca
5 mode 0.0942 1 pca
6 speechiness -0.121 1 pca
7 acousticness 0.399 1 pca
8 instrumentalness 0.370 1 pca
9 liveness -0.118 1 pca
10 valence -0.295 1 pca
# ℹ 215 more rowsLet’s make this a plot!
colors <- fishualize::fish_pal(option = "Centropyge_loricula")(5)[3:4]
terms %>%
filter(component <= 3) %>%
mutate(terms = tidytext::reorder_within(terms, by = value, within = component)) %>%
ggplot(aes(value, terms, fill = factor(sign(value)))) +
geom_col() +
scale_fill_manual(values = colors) +
facet_wrap(~component, labeller = label_both, scales = "free") +
tidytext::scale_y_reordered() +
guides(fill = "none")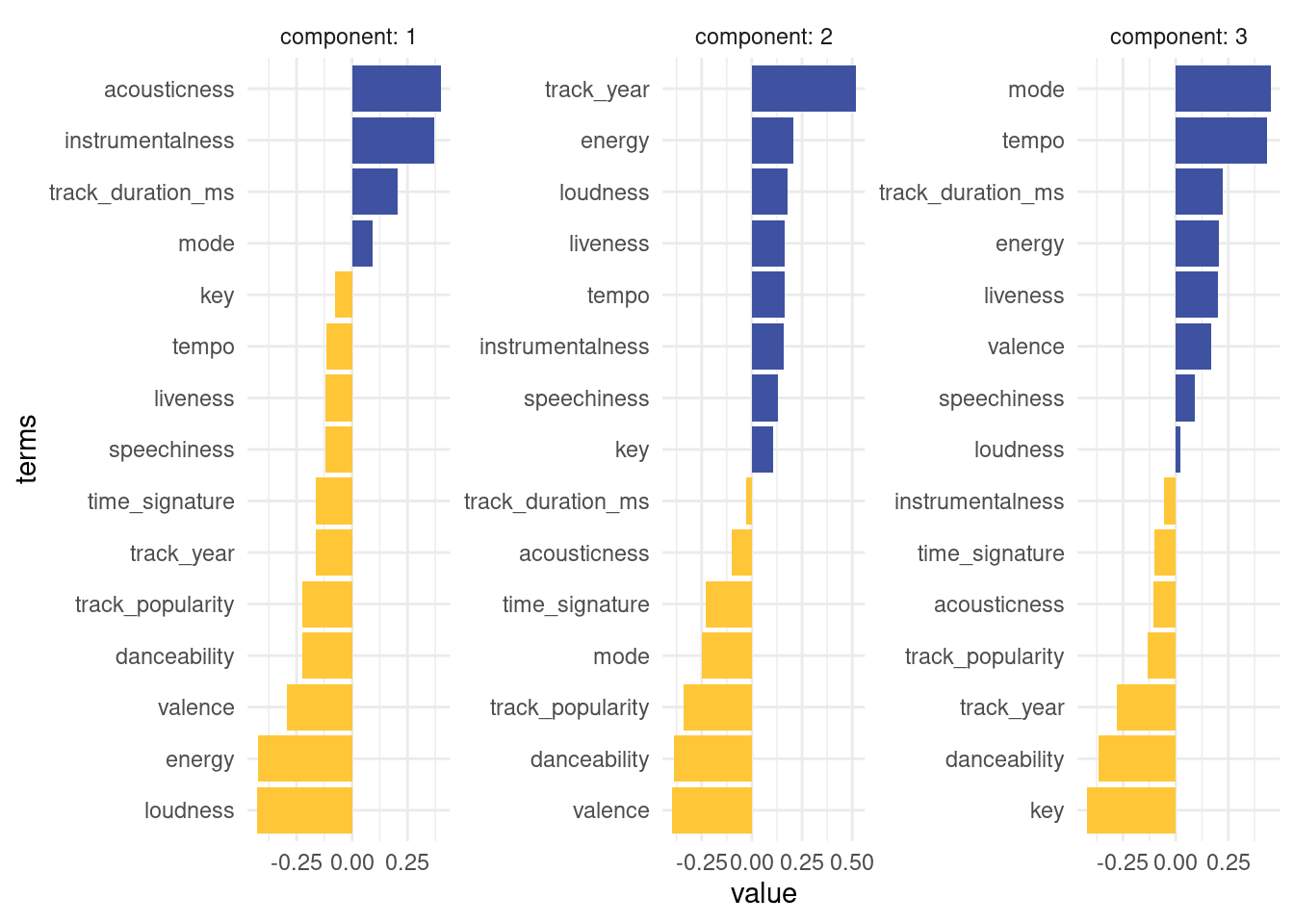
We had to use 2 little helper functions from the tidytext package to properly order the bar. The first component is largely comprised of a high acousticness and instrumentalness and less energy in the positive direction. So we expect e.g. classical music to be very high on that axis. A high value on the second component means a high danceability while being low in tempo.
So where do our songs end up in principle component space?
plt <- songs_baked %>%
ggplot(aes(PC1, PC2)) +
geom_point(aes(text = paste(track_name, ",", track_artists)))
plotly::ggplotly(plt)You can now imagine, using this simpler representation of the songs in principal component space, to for example propose new songs to users based on songs that are close to songs they listened to in this representation.
Lastly, I want to stress, that the principal components are not created equal. The first component is always the most important. Here, we see, that almost 27% of the variance can be explained just by the first component, so exploring more than 2 really makes little sense here.
tidy(songs_prep)# A tibble: 3 × 6
number operation type trained skip id
<int> <chr> <chr> <lgl> <lgl> <chr>
1 1 step naomit TRUE TRUE naomit_nB6On
2 2 step normalize TRUE FALSE normalize_n2kdf
3 3 step pca TRUE FALSE pca tibble(
sdev = songs_prep$steps[[3]]$res$sdev,
explained_variance = sdev^2 / sum(sdev^2),
pc = 1:length(sdev)
) %>%
ggplot(aes(pc, explained_variance)) +
geom_col(fill = "darkgreen") +
geom_text(aes(label = scales::percent_format()(explained_variance)),
size = 3,
vjust = 1.1,
color = "white") +
scale_y_continuous(labels = scales::percent_format()) +
labs(x = NULL, y = "Percent variance explained by each PCA component")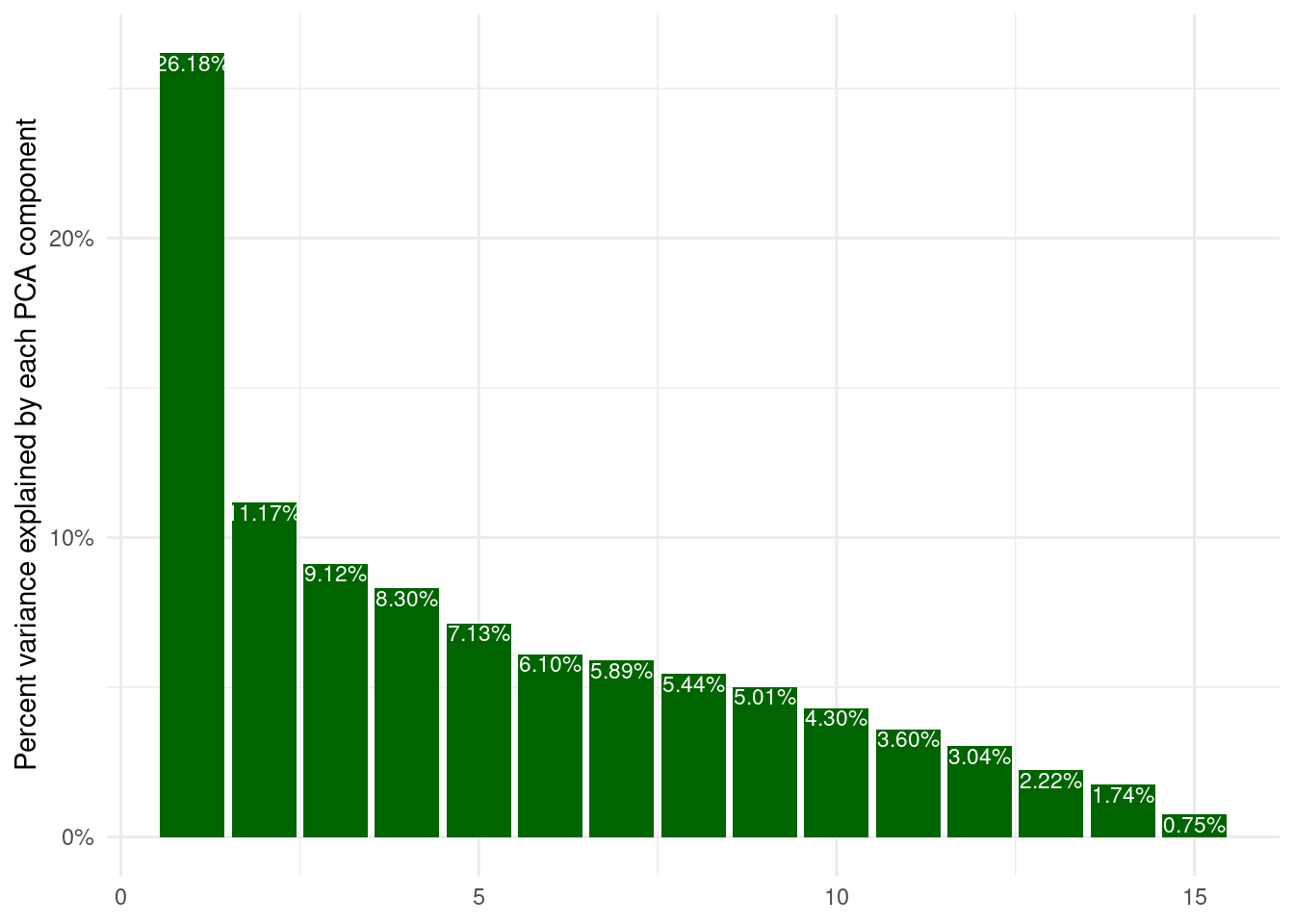
6.14 Exercises
The tidytuesday project also had a spotify dataset. This one es even more interesting, because it ranges across different playlists of various genres and is annotated with said genres. And it has more data (Over 30000 songs)! Download it here:
https://github.com/rfordatascience/tidytuesday/blob/master/data/2020/2020-01-21/readme.md
6.14.1 The Plotty Horror Picture Show
Sometimes we have to experience true horror to see the light in the darkness. Take the spotify data and make a plot that is truly horrible! I would appreciate a couple of sentences about your thought process and what makes your plot particularly bad. You can strike terror into the reader’s heart in multiple ways. Here are some ideas, mix and match what suits you:
- Make it really ugly by experimenting with different theme options.
- Make it really misleading by defying viewer expectations and breaking all norms. You are an artist now, norms don’t apply to your art.
- What even are axis labels?
- Experiment with different (manual) color schemes! Using Red and Green is an excellent choice if you want to make sure your plot is unreadable for every 12th man (due to the high prevalence of red-green-blindness).
- Try out different geoms and combinations of aesthetics, maybe find the ones that are the worst possible choice for the features.
6.14.2 Take a Sad Plot and Make it Better
The title of this exercise is stolen from this talk by Alison Hill.
Now use what you learned to make a great plot! Pick some features that you are interested in and visualize them as informative and beautiful as possible, while still staying honest to the data. Maybe you are interested in changes over time, maybe you find your favorite artist and want to situate them in the context of other works. Maybe you want to explore how different features relate to each other or even want to attempt to recreate the PCA to see, if you can find clusters of genres. It is your call.
I am curious to see, what you come up with!